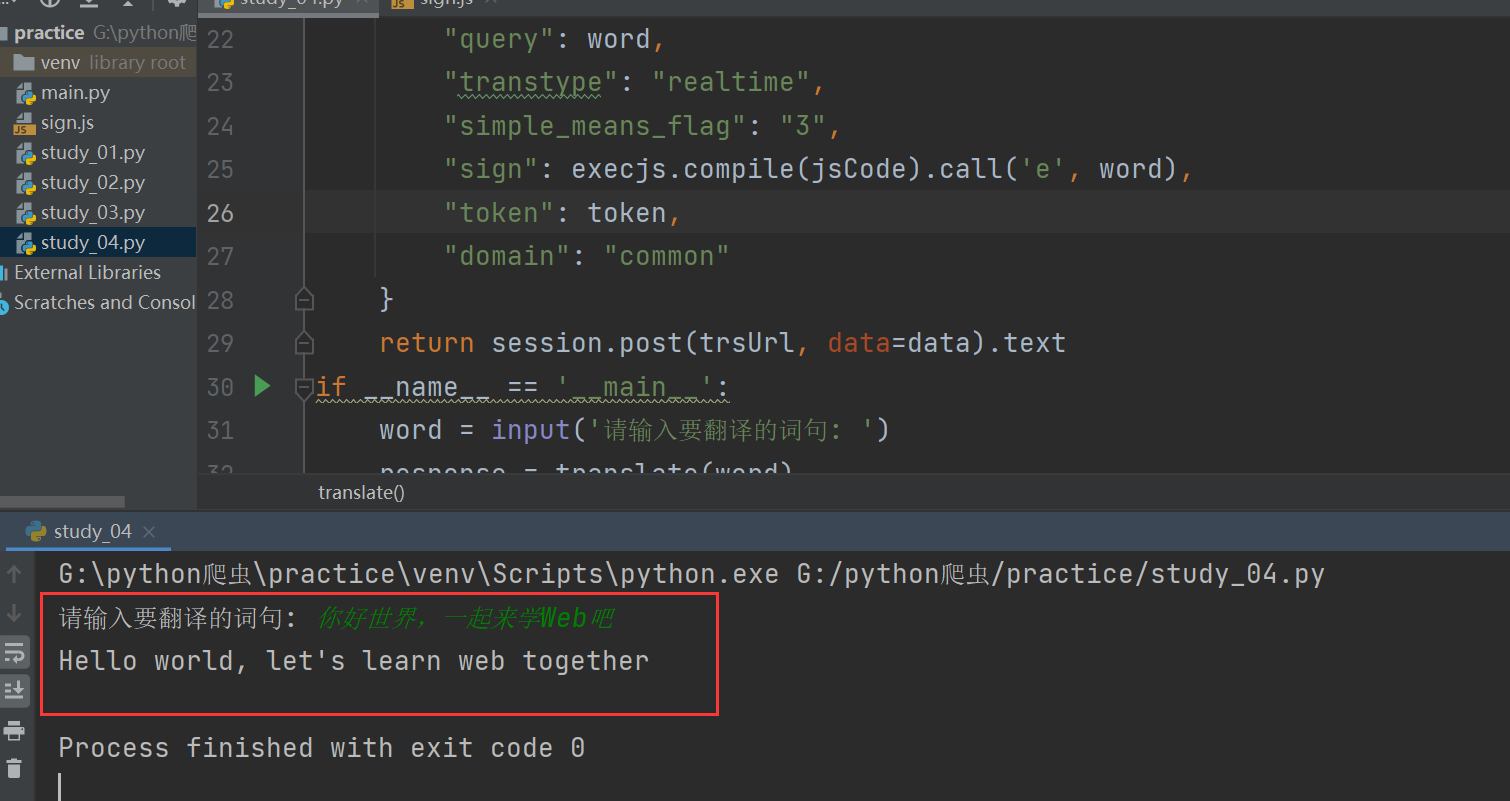
最近简单学习了一下 requests 这个模块,一直没有亲自实战一下,然后就有了这次的实战练习
浏览器F12对百度翻译进行抓包
随便输入一个词句抓包
我们主要要获取这里的数据
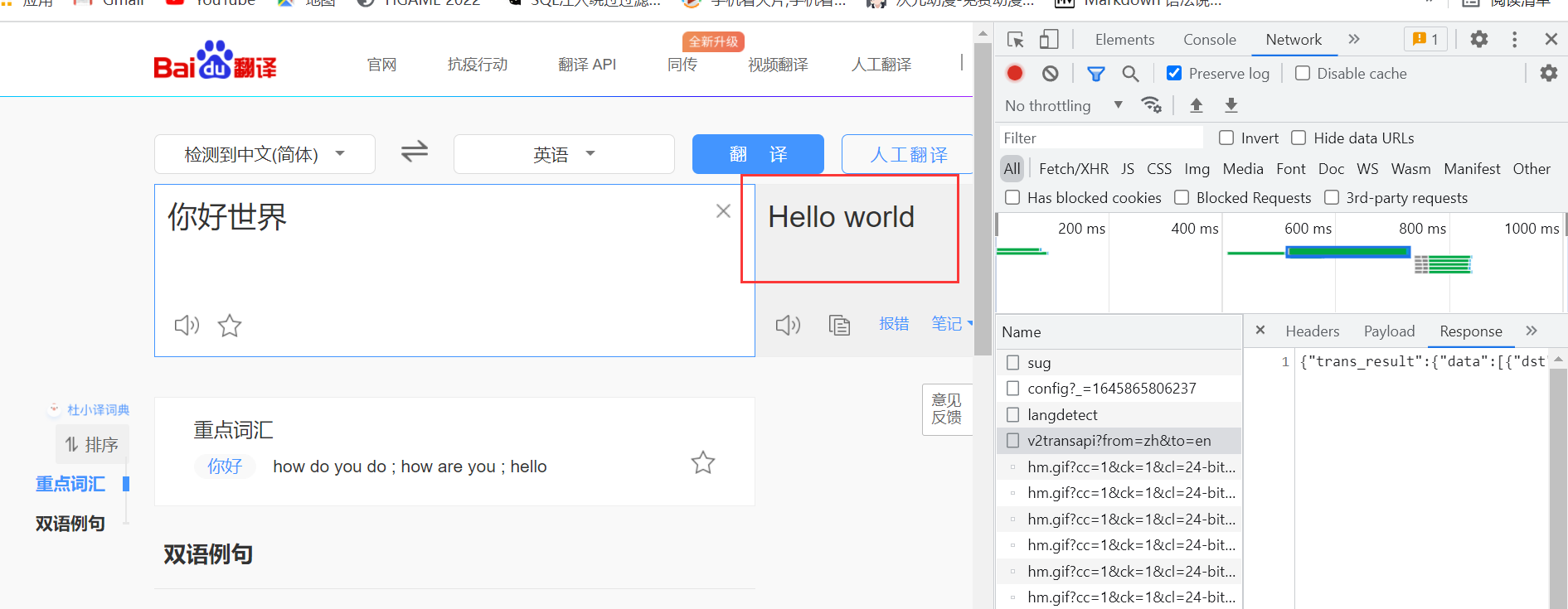
而这里的数据是对https://fanyi.baidu.com/v2transapi?from=zh&to=en这个链接发起的一次post请求
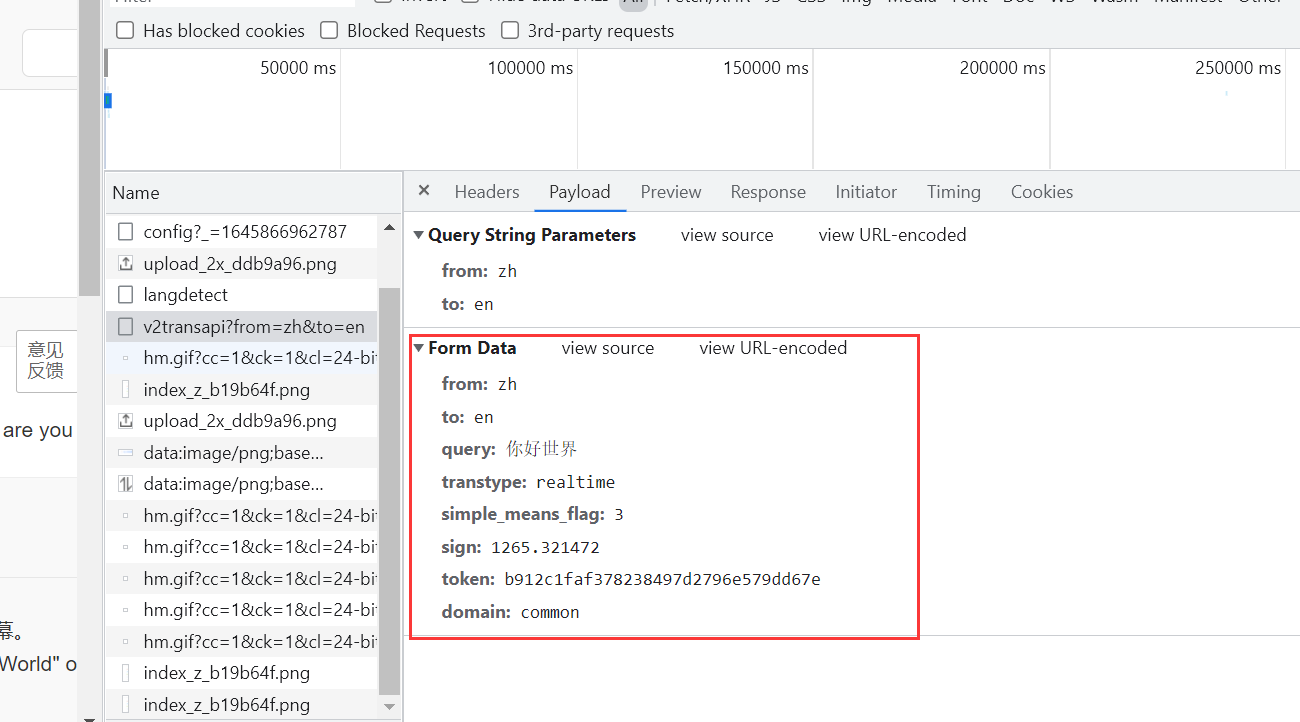
可以看到请求表单中发送的关键数据
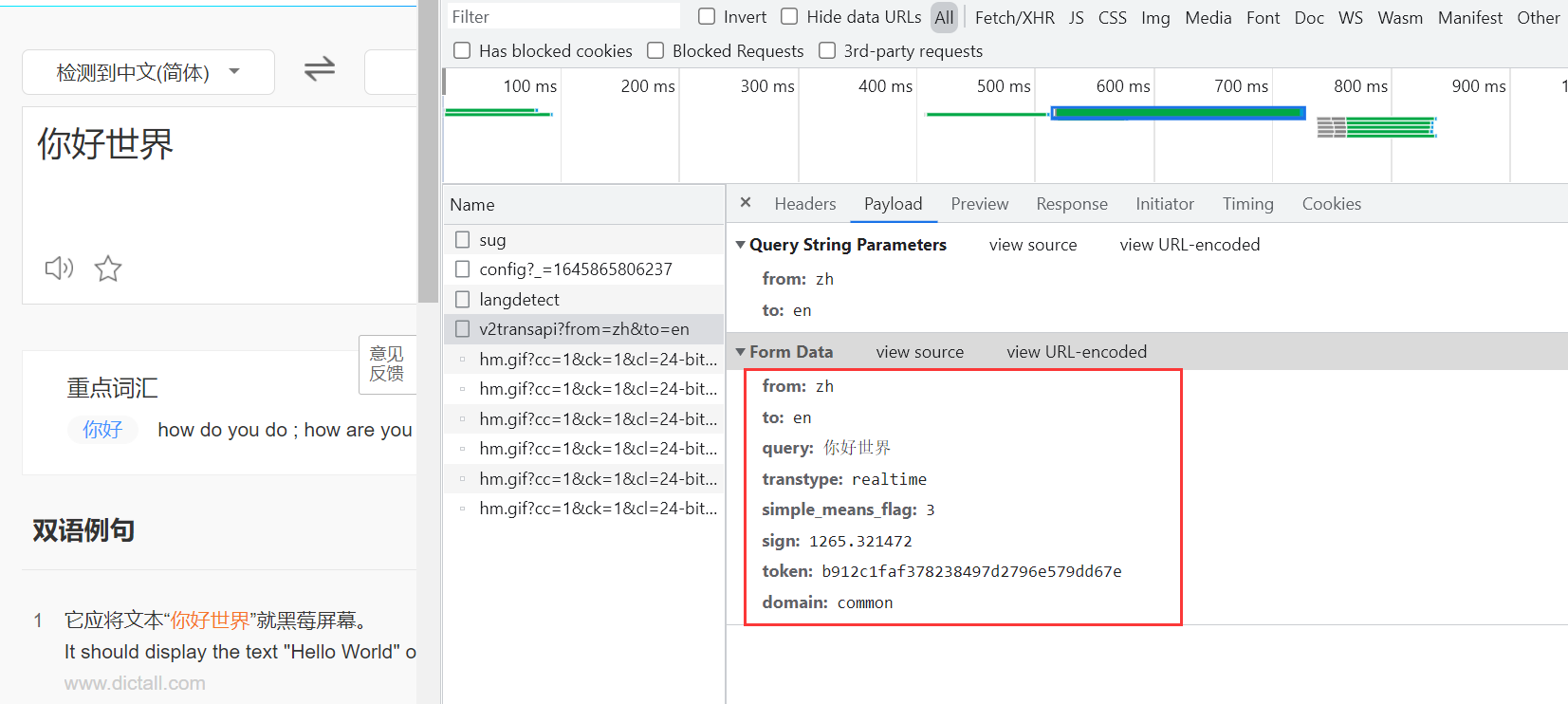
尝试其他词句发现主要变化的是sign,还有token这两个关键变量
在当前页面审查元素就能发现这个token
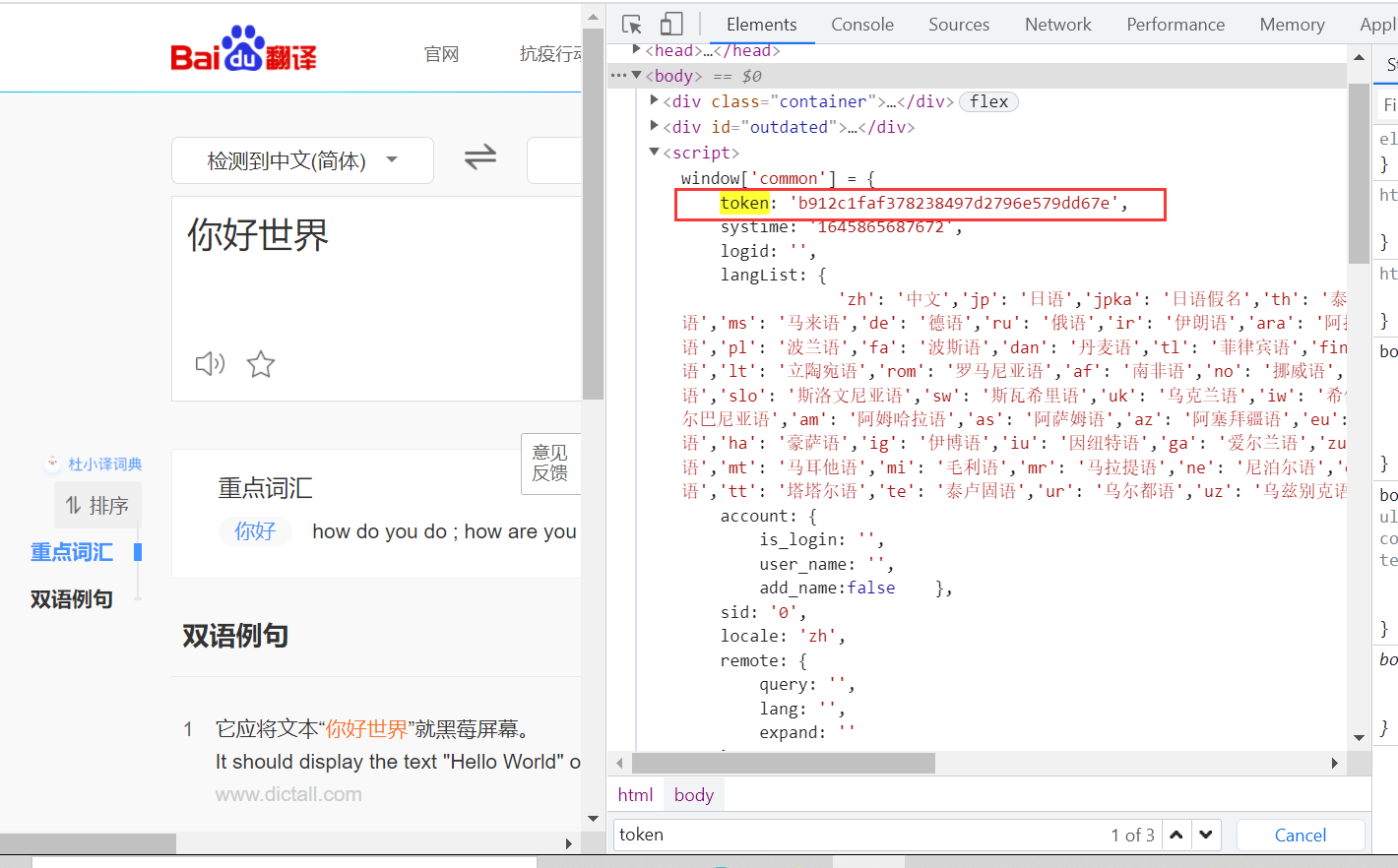
现在关键是这个sign
查看一下这个post方法的请求栈
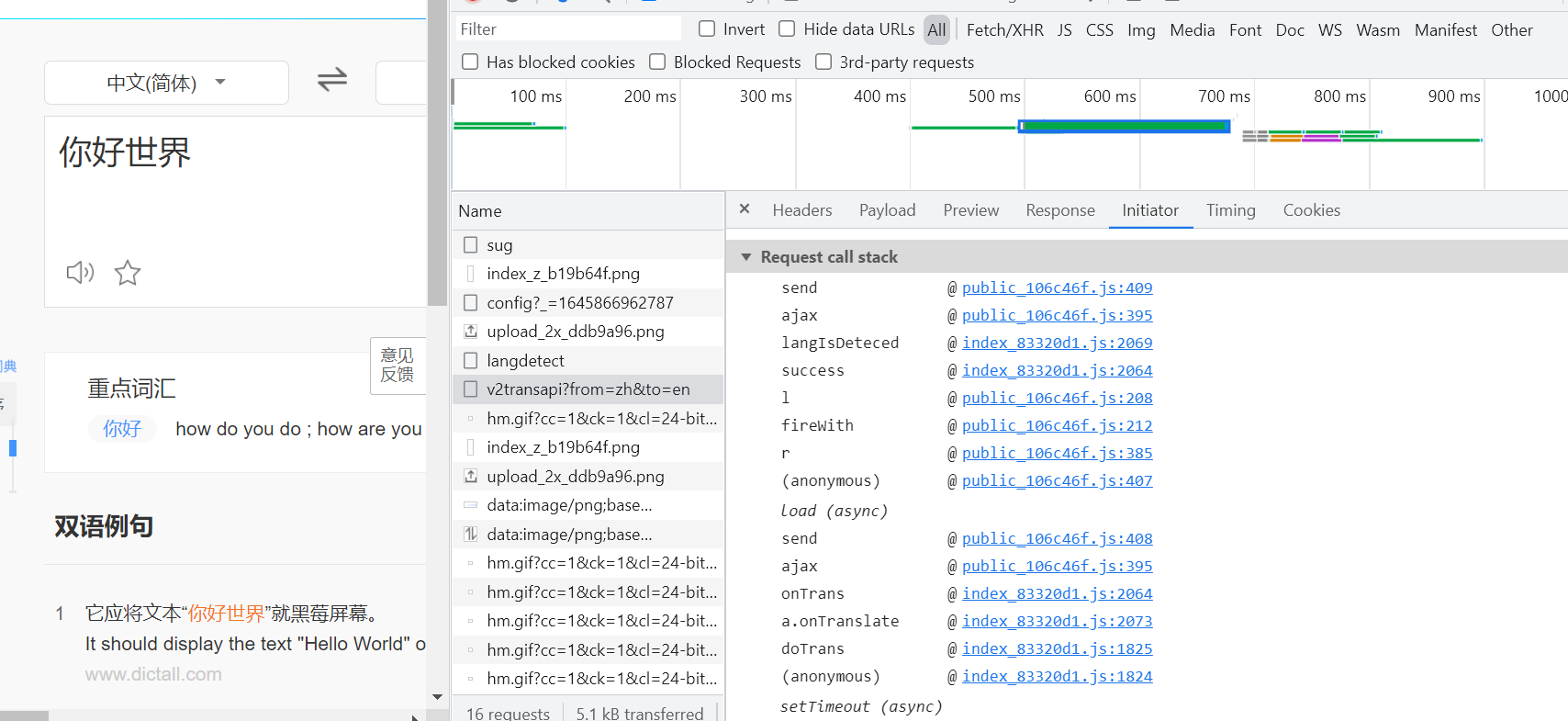
主要是index和public这两个js文件,打开搜索一下payload中的sign,发现在index这个js文件里有这个payload
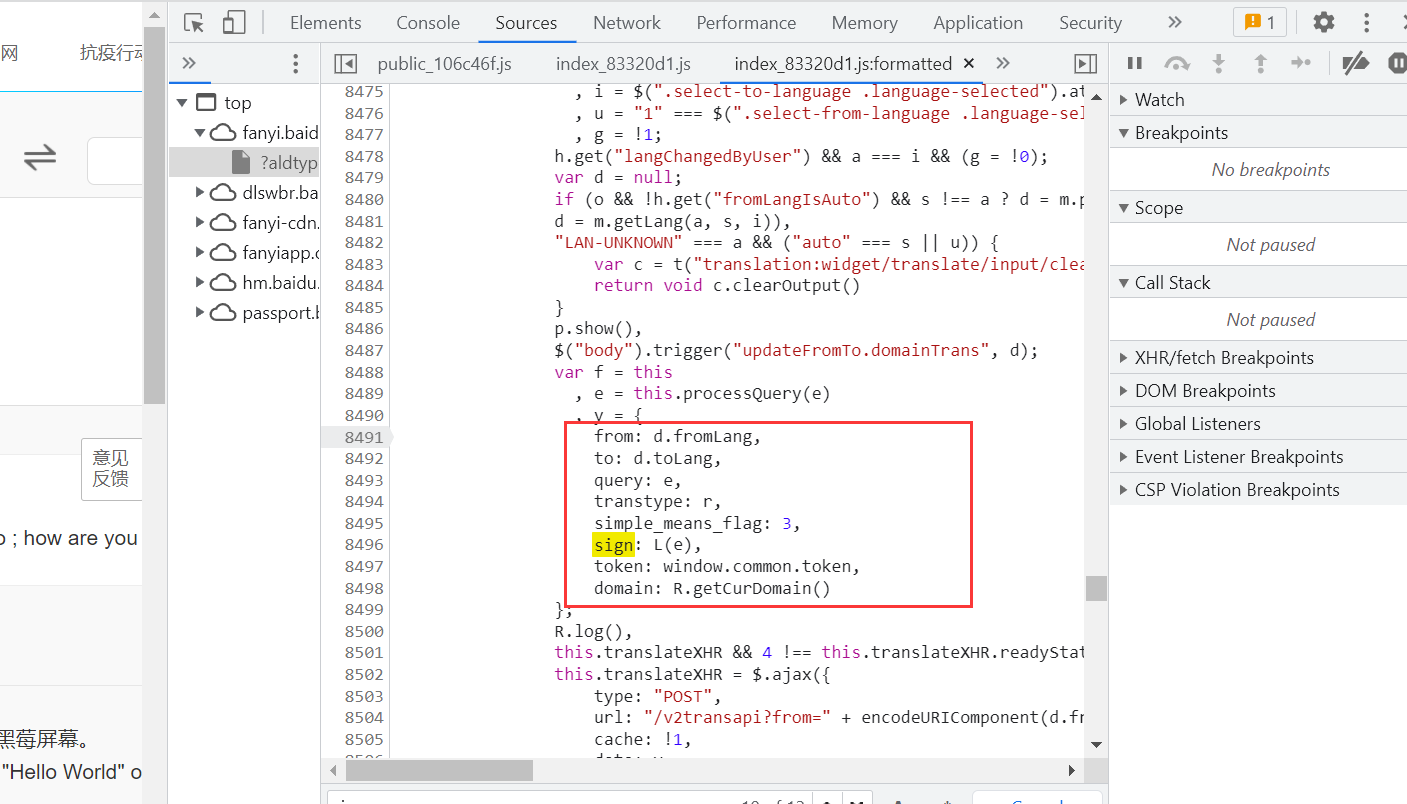
可以发现这里和post表单中的数据格式一样
现在看看这个sign它是怎么生成的
在sign: L(e)这里打一个断点调试一下
刷新页面,来到这个sign处,然后点击单步调试
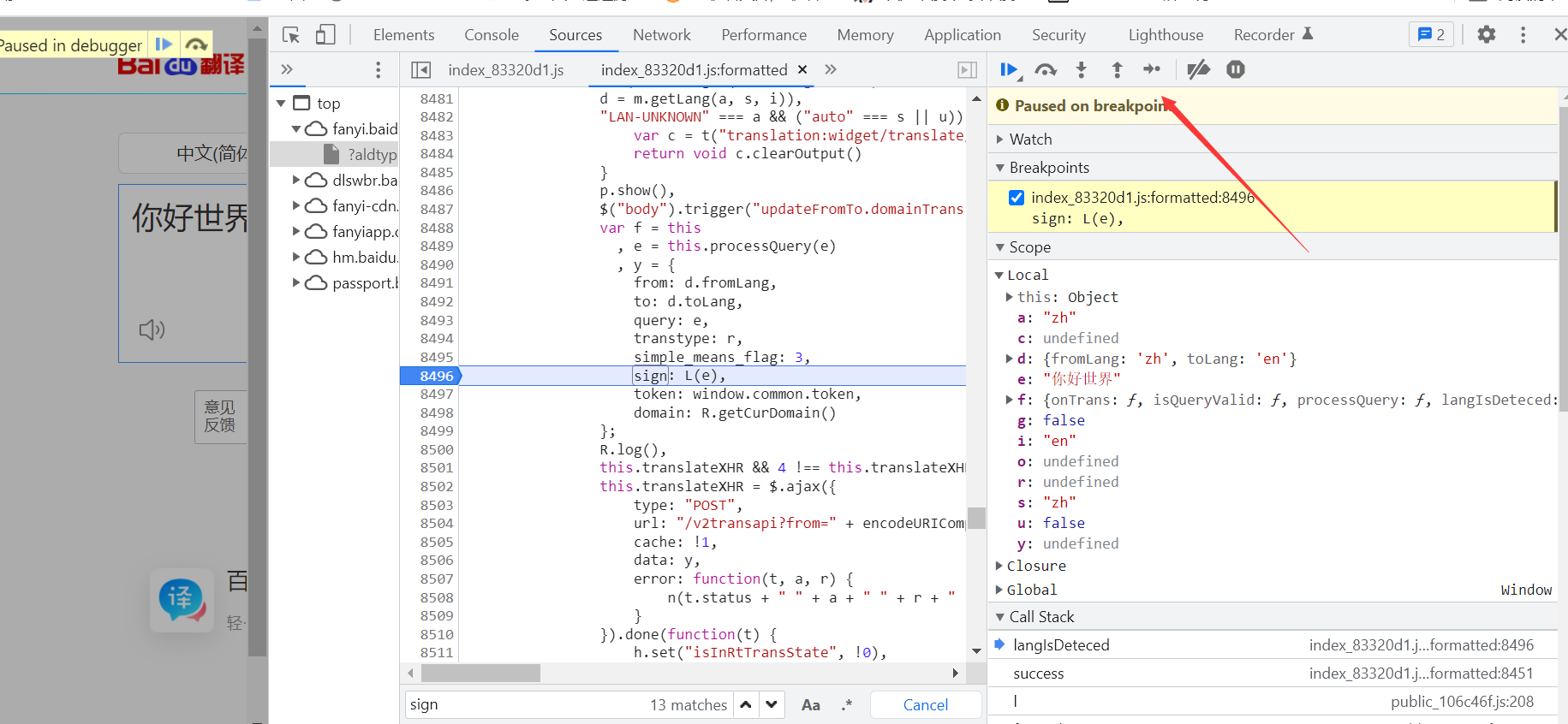
然后跳转到了e(r)这个函数,这个应该就是生成sign的函数
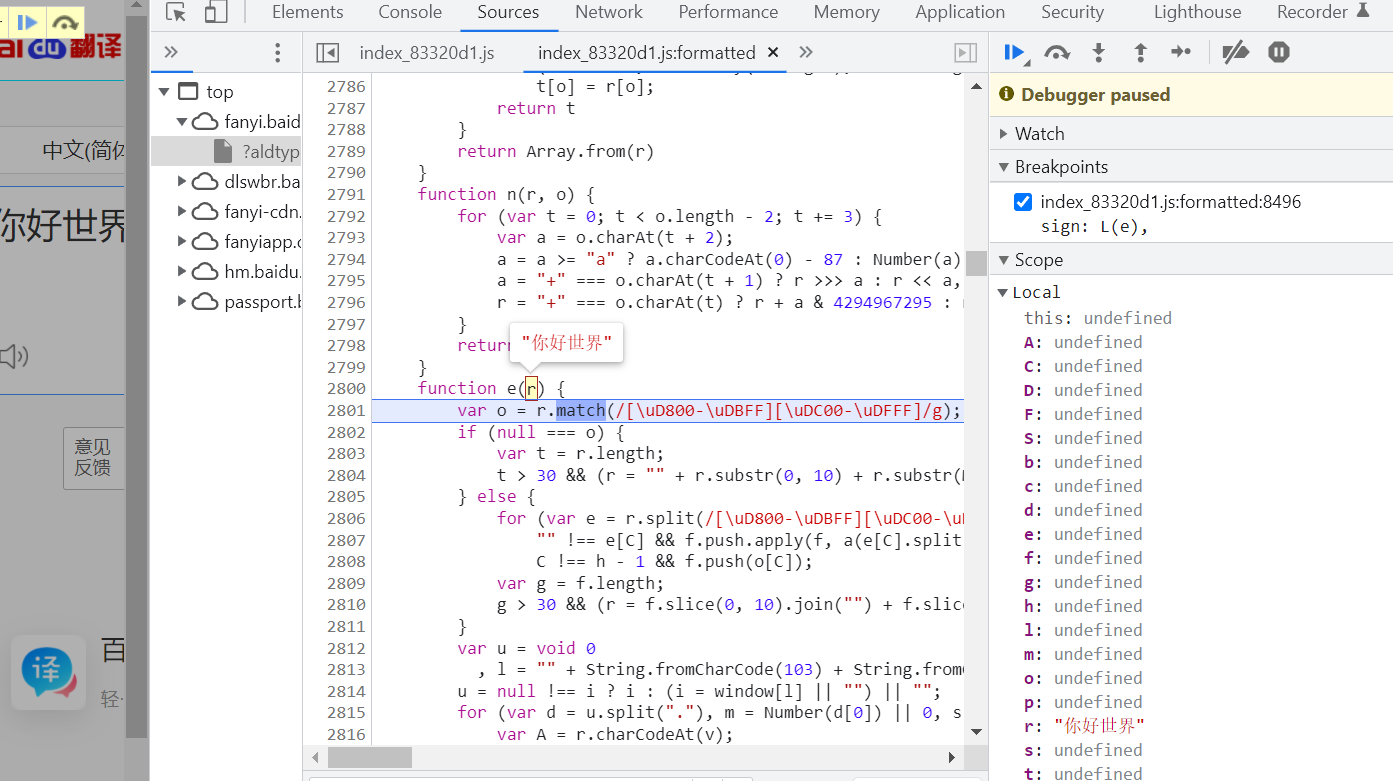
同时发现传递的参数正好是你输入的词句
那么继续单步调试,到函数的末尾发现又调用了一个n(r, o)函数
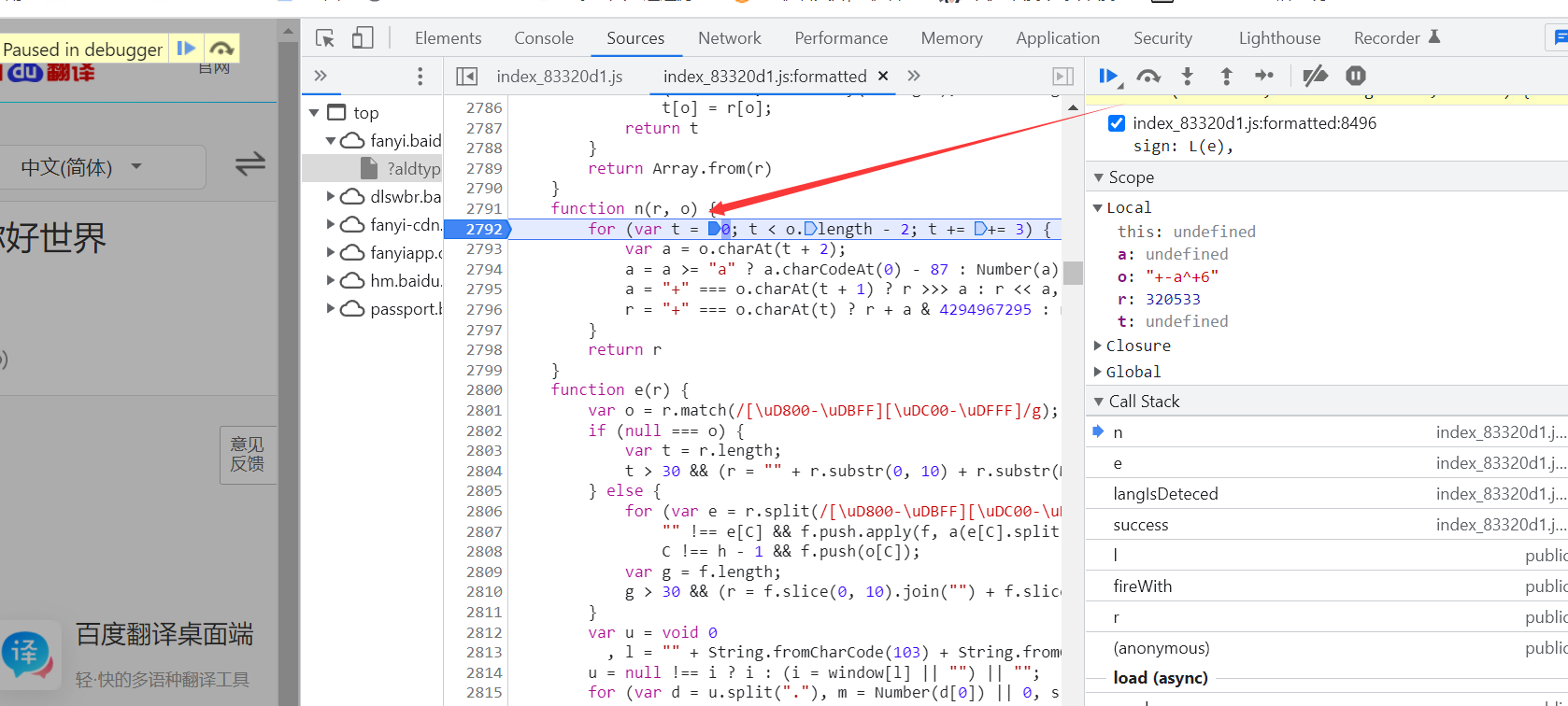
继续运行,结束
经过上面的调试发现,这个sign就是使用了上面两个函数对输入的词句进行加密操作,具体的算法比较复杂,不需要搞懂它,我们可以使用python中的execujs这个库来运行,这个js代码,得到加密后的sign
先不要急,在浏览器跑一下这个加密代码
cv到控制台,输入参数运行
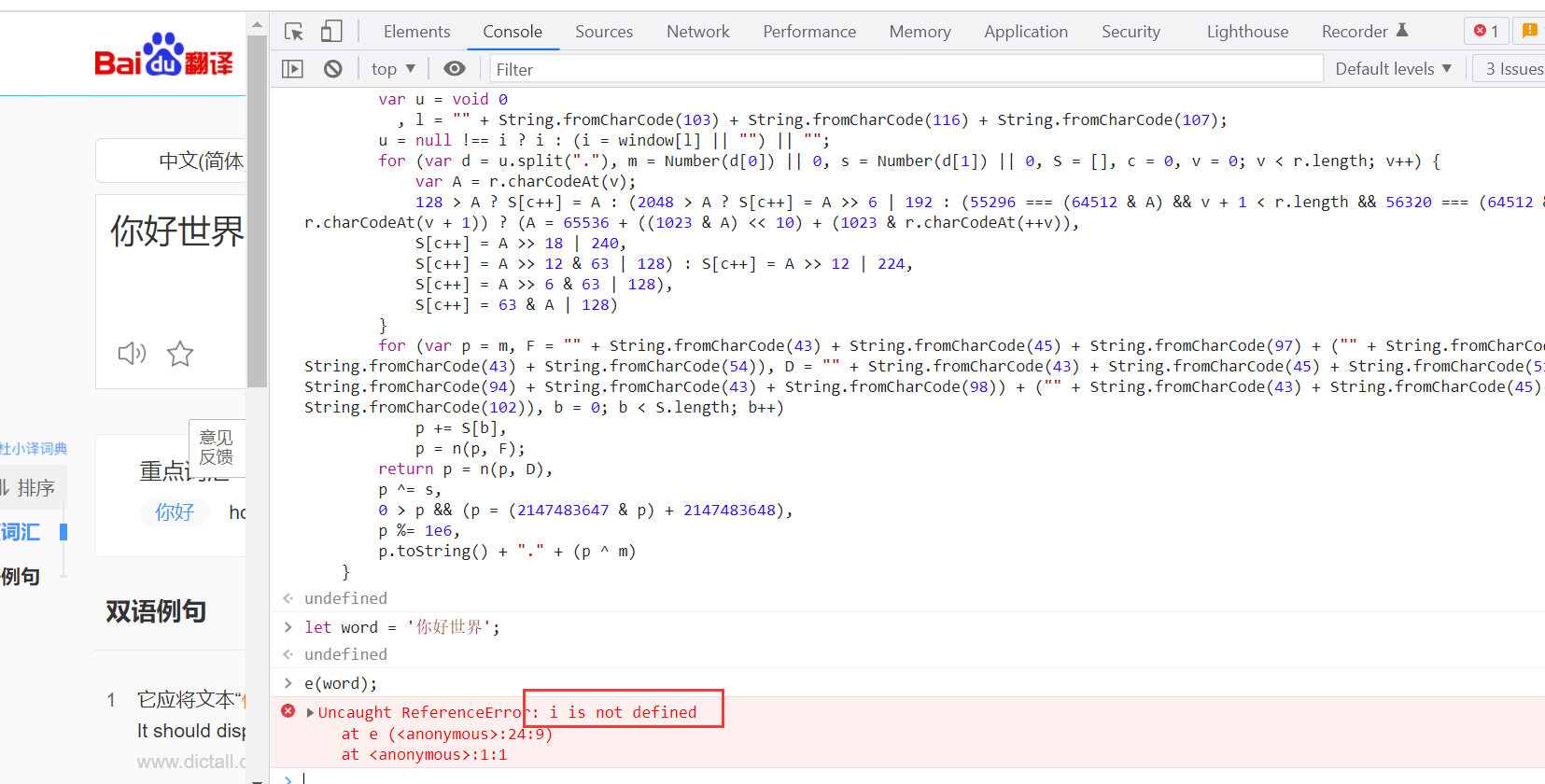
发现报错了,查看报错列表知道是 i 这个变量没有定义
那么继续回到原来的调试
找到这个变量 i ,打个断点
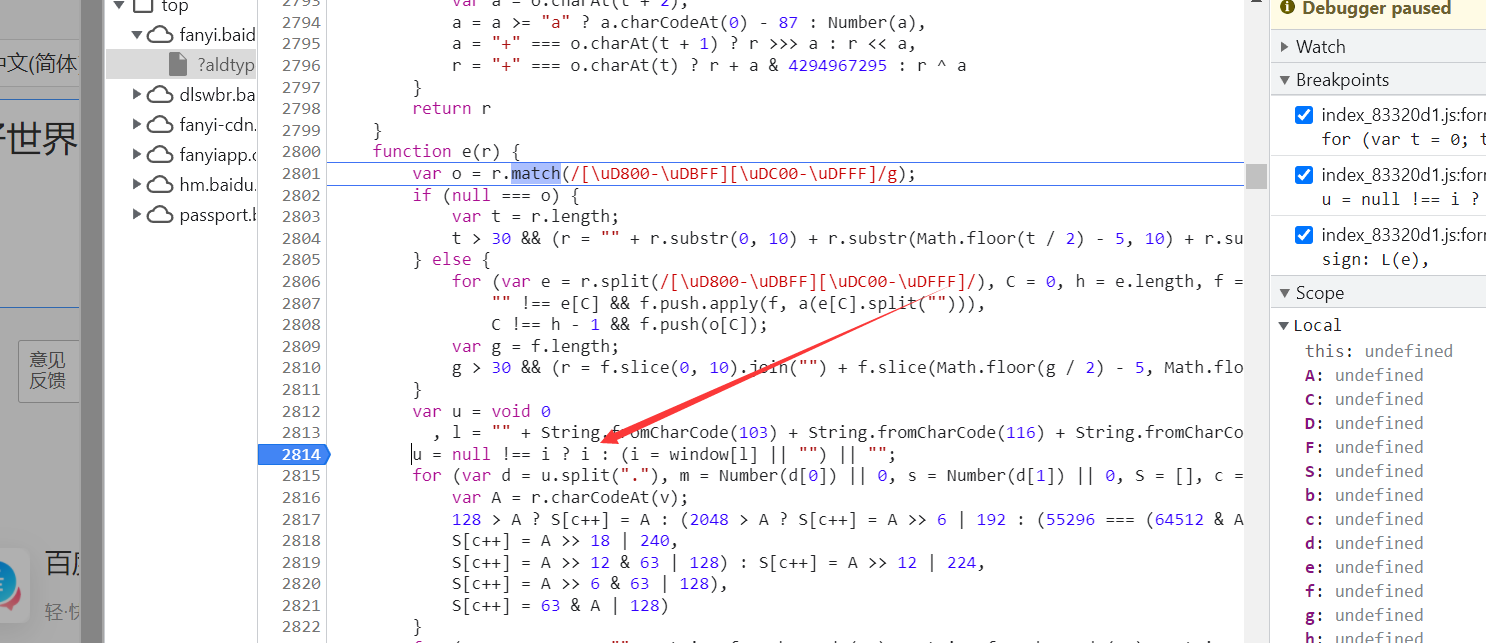
运行,发现这个变量 i 的值为 320305.131321201
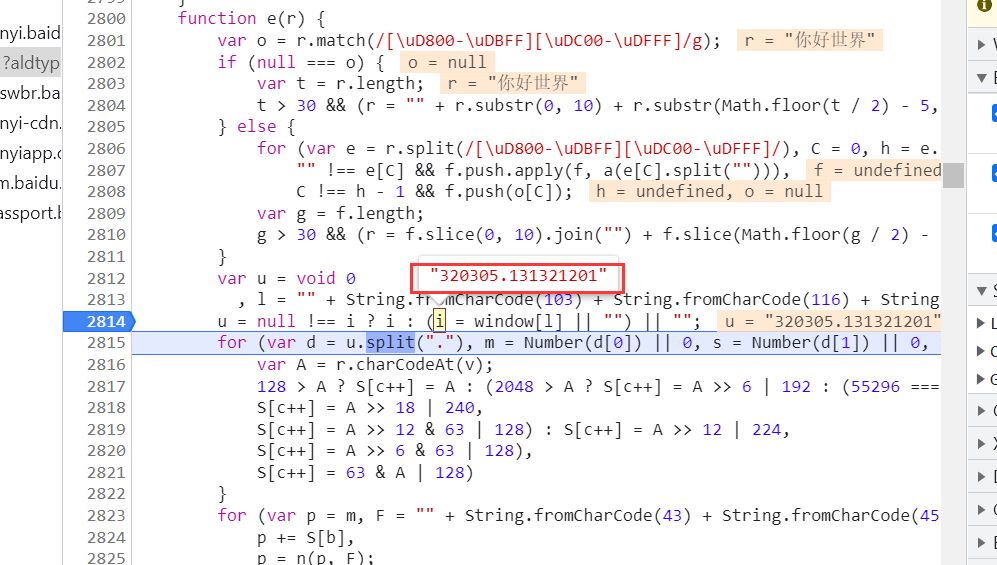
改变输入的词句发现这个 i 始终是个定值,都是 320305.131321201 ,那么现在所有的问题基本上就解决了,
剩下的就是写爬虫脚本,代码如下
对应 sign 的js代码
i = '320305.131321201';
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= 'a' ? a.charCodeAt(0) - 87 : Number(a),
a = '+' === o.charAt(t + 1) ? r >>> a : r << a,
r = '+' === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = '' + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr( - 10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = [
]; h > C; C++) '' !== e[C] && f.push.apply(f, a(e[C].split(''))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join('') + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join('') + f.slice( - 10).join(''))
}
var u = void 0,
l = '' + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = null !== i ? i : (i = window[l] || '') || '';
for (var d = u.split('.'), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [
], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)
}
for (var p = m, F = '' + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ('' + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = '' + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ('' + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ('' + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++) p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1000000,
p.toString() + '.' + (p ^ m)
}python脚本
import execjs
import requests
import re
import json
mainUrl = 'https://fanyi.baidu.com'
trsUrl = 'https://fanyi.baidu.com/v2transapi'
with open('sign.js', 'r') as file:# sign.js从浏览器对应的文件中复制过来
jsCode = file.read()
session = requests.session()
indexResp = session.get(mainUrl)
token = re.findall("token: '(.*?)'", indexResp.text)[0]
def translate(word):
data = {
# 这里将from和to参数改为auto发现可以任意语言翻译为中文,中文翻译为英文,可自动切换
"from": "auto",
"to": "auto",
"query": word,
"transtype": "realtime",
"simple_means_flag": "3",
"sign": execjs.compile(jsCode).call('e', word),
"token": token,
"domain": "common"
}
return session.post(trsUrl, data=data).text
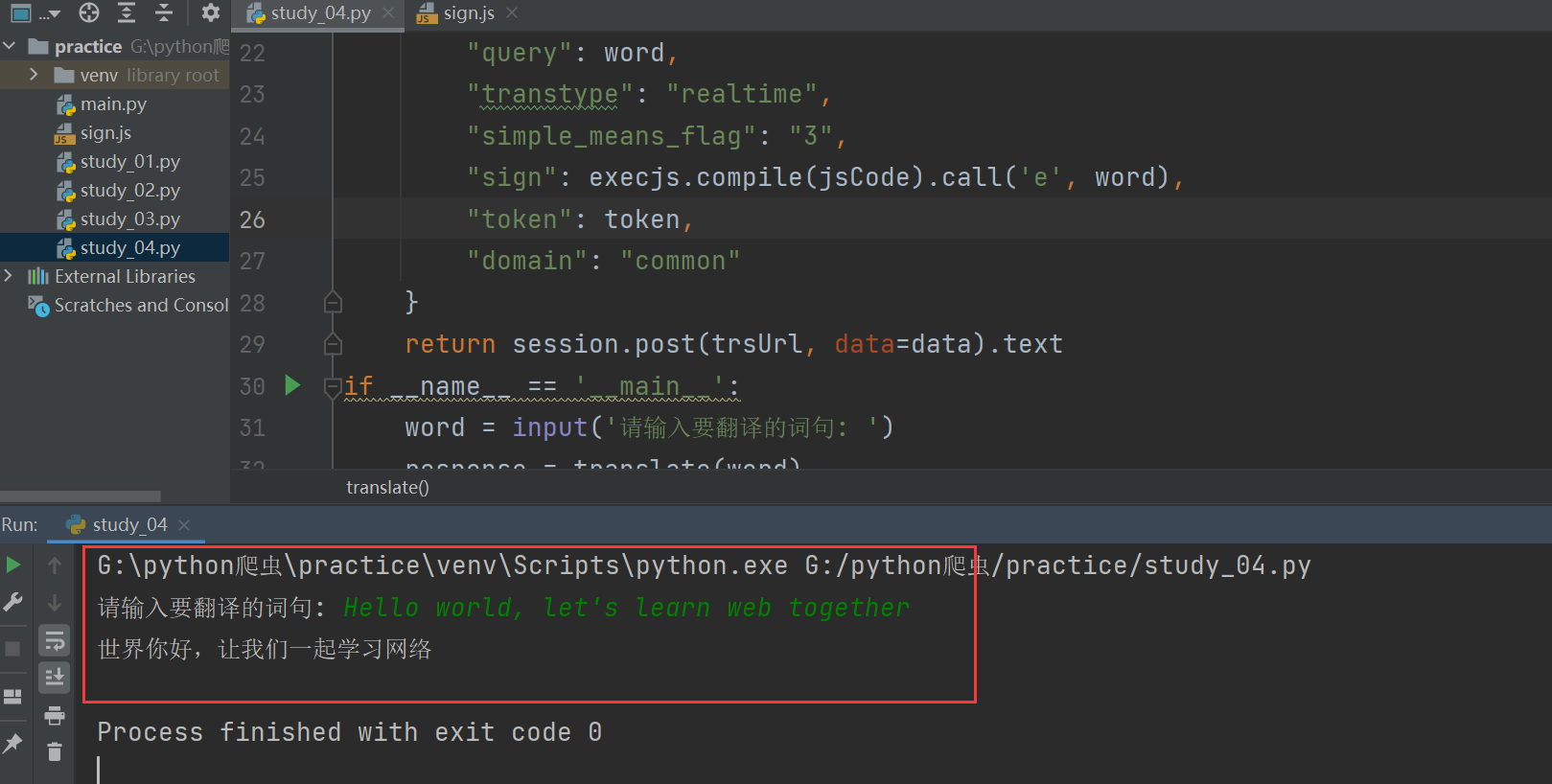
if __name__ == '__main__':
word = input('请输入要翻译的词句: ')
response = translate(word)
print(json.loads(response)['trans_result']['data'][0]['dst'])最后测试,中英文都没问题